Imagine spotting a friend in a crowded train station. You catch only a glimpse—a shoulder, a bit of hair, the way they walk. Instantly, your brain fills in the rest: the face, the body, the identity. No second thought, no hesitation. You just know. This almost magical ability, where the mind pieces together visual fragments to recognize a whole, is called contour integration—a process so effortless for humans, we barely notice it happening.
Yet for artificial intelligence, even the smartest systems in the world, this task remains staggeringly hard.
A new study by researchers at EPFL’s NeuroAI Lab has put this gap between human and machine vision under the microscope. Their findings, presented at the 2025 International Conference on Machine Learning (ICML) and available on the arXiv preprint server, reveal a fundamental difference between how brains and algorithms see the world—and why that difference matters more than we might think.
Why AI Still Fails to See the Big Picture
Despite massive breakthroughs in computer vision, AI still struggles when the picture isn’t perfect. If an object is hidden behind something else, obscured in fog, or fragmented into scattered parts, many AI models fail to recognize it. They mislabel a cup as a bowl, or worse, guess randomly. It’s a serious flaw, especially in high-stakes fields like autonomous driving, prosthetics, medical imaging, and robotics, where seeing clearly can mean the difference between safety and disaster.
“The gap we’re seeing between humans and AI isn’t about raw computing power,” said Martin Schrimpf, head of the NeuroAI Lab at EPFL. “It’s about how we interpret what we see. The human brain is a master at seeing connections, even when the pieces are missing.”
A Laboratory Puzzle with Real-World Implications
To explore this difference, Schrimpf’s team designed a large-scale study that put both humans and machines to the test. Ben Lönnqvist, a doctoral student in EPFL’s EDNE program and lead author of the study, worked with the Laboratory of Psychophysics led by Michael Herzog to create a series of visual puzzles—images of ordinary objects with their outlines erased or broken into fragments.
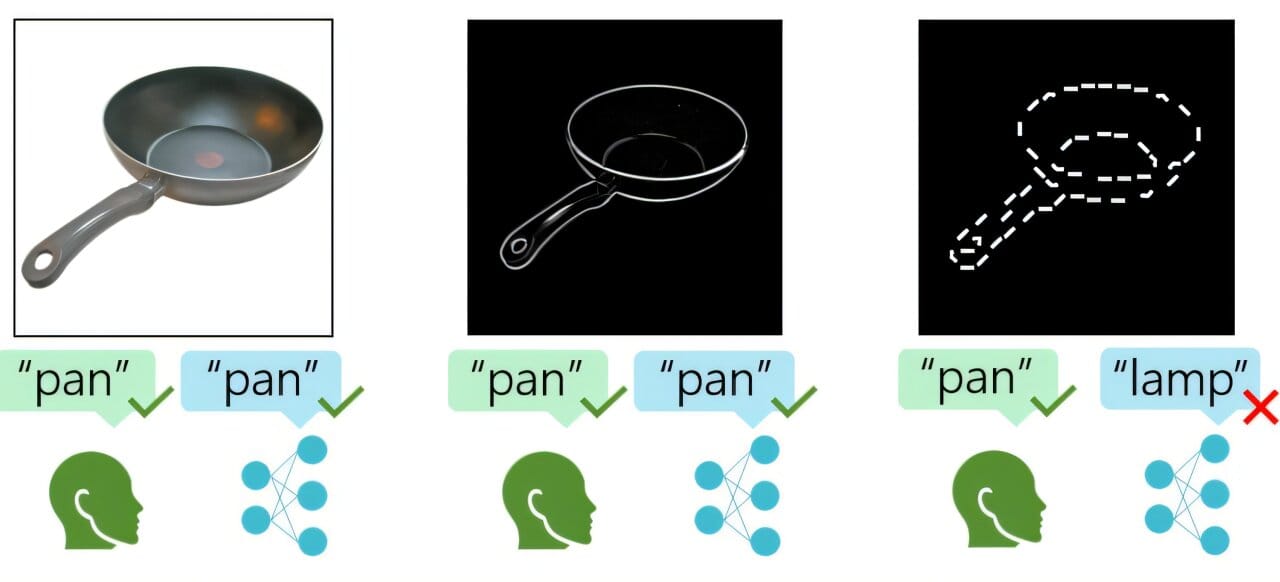
The challenge was simple but revealing: Could participants still recognize a hat, a pan, or a boot if only part of its contour remained?
The human test group included 50 volunteers who viewed hundreds of these broken-outline images in the lab. At times, they had as little as 35% of the original outline to work with. The same exact images were then fed to over 1,000 artificial neural networks—ranging from smaller academic models to some of the world’s most advanced vision AI systems.
The researchers tracked performance across 20 different conditions, varying the amount and type of visual information. The results were telling. Humans, even with missing or scrambled contours, remained astonishingly accurate—sometimes identifying objects correctly 50% of the time, far above random guessing.
AI models, on the other hand, faltered as soon as the full shape disappeared. Without complete outlines or surface texture, most models collapsed into confusion, often producing guesses that were no better than chance.
Uncovering the Brain’s Visual Bias
But the study didn’t stop at measuring success rates. The researchers wanted to know why humans did so well and whether AIs could be trained to do better.
One crucial insight emerged: humans have what the researchers called an “integration bias.” When pieces of a contour point in the same direction—like the arch of a handle or the curve of a rim—the brain naturally stitches them together. Even when those fragments are spaced apart or distorted, our minds lean toward interpreting them as one coherent object.
This preference, it turns out, isn’t hardwired. It’s learned. And that’s good news for AI.
“When we trained models to recognize this bias, they got better,” Lönnqvist explained. “We saw that AI could improve not just by changing its structure, but by changing what it pays attention to—shapes over textures, contours over color.”
By giving AI systems a visual diet that more closely mirrors human experience—images where objects are partly hidden, sliced, or incomplete—the researchers were able to boost performance. Some models even approached human-like robustness under fragmented conditions, though they still required orders of magnitude more data to do so.
Teaching Machines to See Like Us
These findings shine a light on an overlooked pathway to smarter, safer AI. Instead of building ever-larger models with more layers and parameters, perhaps what machines need is not more brain, but better vision—not just sharper eyes, but wiser ones.
In real-world environments, visual information is rarely perfect. A child dashes behind a parked car. A doctor scans an obscured tumor. A rescue robot must identify debris and danger in a collapsed building. In each case, relying on clear, complete imagery is unrealistic. The human ability to recognize patterns from fragments gives us a unique advantage. If AI is to match us, it must learn to see not only what is, but what could be.
Michael Herzog, co-author of the study, put it simply: “Understanding how humans see helps us build machines that can understand the world—not just scan it.”
A New Frontier for Human-AI Collaboration
This study marks a turning point. It’s not just about improving object recognition. It’s about shifting the philosophy behind artificial vision. It suggests that to make AI more robust, we don’t have to reinvent intelligence—we can mirror our own.
That approach could ripple across industries. In autonomous vehicles, for instance, teaching systems to rely more on contour integration could make them better at identifying pedestrians partially blocked by cars or trees. In healthcare, smarter vision algorithms could improve diagnoses from blurry or partial scans. In assistive technology, prosthetics that better interpret a user’s environment could adapt more naturally, offering users safer, more intuitive experiences.
And in a world increasingly shaped by AI, designing systems that see as we do is not just a technological goal. It’s a human one.
Vision as a Mirror of the Mind
The brilliance of this research lies in its humility. It doesn’t promise machines that are better than us—but machines that learn from us. That in itself is revolutionary.
Contour integration may seem like a dry scientific term, but it touches on something profound: the mind’s ability to find order in chaos, to see patterns where others see noise, to imagine wholeness from parts. It’s the foundation of perception, of creativity, even empathy. It’s how we navigate a world full of shadows and silhouettes.
And now, thanks to this work from EPFL, we’re one step closer to building AI that doesn’t just see pixels—but begins to understand the picture.
Reference: Ben Lonnqvist et al, Contour Integration Underlies Human-Like Vision, arXiv (2025). DOI: 10.48550/arxiv.2504.05253