In the twenty-first century, data is the bloodstream of human progress. From personalized recommendations to predictive healthcare, from autonomous vehicles to smart cities, machine learning (ML) has become the silent architect of modern innovation. Yet, the brilliance of a machine learning model in a research lab often falters when confronted with the chaos of real-world deployment. The gulf between experimentation and execution has long been the Achilles’ heel of AI-driven transformation. Bridging this gap gave birth to a new discipline—MLOps, or Machine Learning Operations.
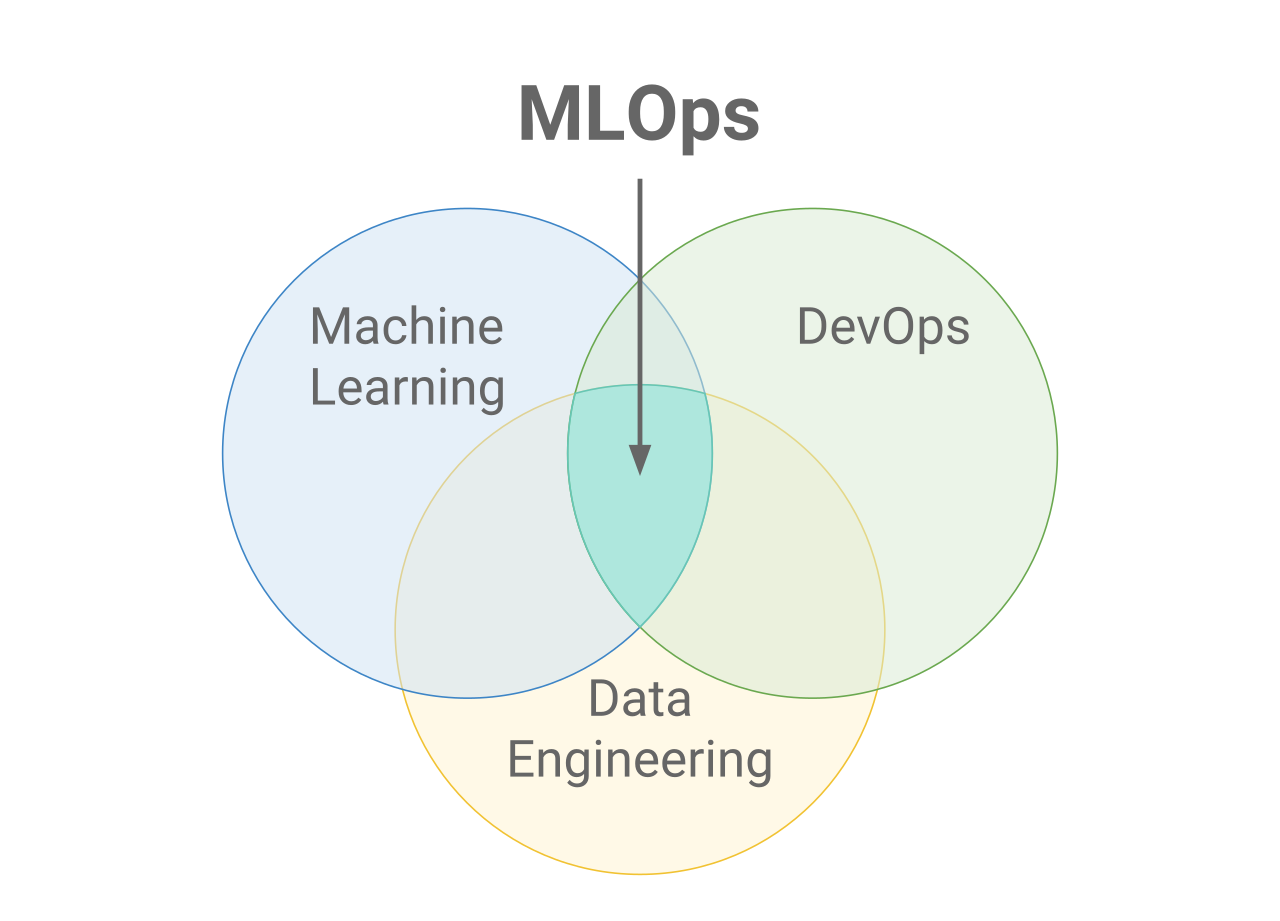
MLOps represents a cultural and technological shift, combining the agility of DevOps with the intelligence of machine learning. It is the backbone that transforms static algorithms into living systems—systems that learn, adapt, and deliver value continuously. It is the science of turning prototypes into production-grade intelligence, of ensuring that models do not merely exist but thrive amid evolving data, unpredictable users, and ever-changing business realities.
Just as DevOps revolutionized software delivery through automation and collaboration, MLOps does the same for the machine learning lifecycle. It integrates the creativity of data scientists, the precision of engineers, and the rigor of operations teams. The result is an ecosystem where ideas flow into production seamlessly, where models are not just built but managed, monitored, and maintained as dynamic, evolving entities.
The Challenge of Machine Learning in the Real World
To appreciate the importance of MLOps, one must first understand the fragility of traditional machine learning workflows. In research settings, models are developed in controlled environments—static datasets, predefined metrics, and neatly packaged code. Yet, once deployed, they enter a world defined by noise, drift, and uncertainty.
A model predicting customer churn, for instance, might perform admirably during testing but degrade rapidly once customer behavior shifts. A computer vision model trained on daylight images might stumble under different lighting conditions. The problem is not in the algorithms themselves, but in the operational gap between experimentation and execution.
Data scientists, by nature, are explorers. They thrive in the uncertainty of data, experimenting with features, algorithms, and hyperparameters. Engineers, in contrast, value consistency, scalability, and reliability. Without a unifying framework, these two worlds clash. Data scientists hand off models as static files, while engineers struggle to integrate, deploy, and monitor them in production. MLOps emerged precisely to dissolve these silos—to make machine learning systems as maintainable, auditable, and scalable as any modern software system.
The Genesis of MLOps
The rise of MLOps was both inevitable and necessary. As machine learning matured, organizations discovered that developing a model was only a fraction of the work. According to industry studies, 80% of machine learning projects fail to move beyond the prototype phase. The reasons are not scientific but operational: lack of version control for data and models, insufficient testing frameworks, manual deployment processes, and weak monitoring mechanisms.
The solution lay in reimagining machine learning as a continuous, cyclical process rather than a linear one. Inspired by the success of DevOps in software engineering, MLOps adapted similar principles—automation, continuous integration, and collaboration—but tailored them to the unique demands of data-driven systems.
The term “MLOps” began gaining traction around 2018, popularized by practitioners and major cloud providers like Google and Microsoft. It encapsulated a vision where model development, deployment, and management formed a cohesive pipeline—an automated ecosystem in which models could evolve alongside data. MLOps is not merely a toolset but a philosophy: a commitment to reliability, scalability, and transparency in the age of intelligent automation.
The Anatomy of MLOps
At its core, MLOps weaves together several disciplines—data engineering, machine learning, software development, and IT operations—into a unified framework. The objective is to automate and streamline the entire machine learning lifecycle, from data collection to model deployment and beyond.
The process begins with data, the raw material of machine intelligence. Data engineers gather, clean, and transform this data into forms suitable for training. Once the data pipeline is established, data scientists step in, crafting models through experimentation, feature engineering, and algorithmic optimization.
But the true essence of MLOps begins after the model is trained. Here, engineers ensure that models are reproducible, version-controlled, and tested rigorously. Continuous Integration (CI) pipelines verify that every new model or code change maintains functional integrity. Continuous Deployment (CD) pipelines then automate the process of releasing these models into production environments.
The lifecycle does not end there. Once deployed, models must be continuously monitored for performance degradation—a phenomenon known as model drift. Feedback loops capture real-world outcomes, enabling retraining and redeployment. This cyclical process ensures that models remain accurate, ethical, and aligned with their intended goals.
In this sense, MLOps transforms machine learning from a one-time project into an ongoing service—a living system that learns not just from data, but from its own operational experience.
Data: The Foundation of Everything
No model is better than the data that shapes it. In MLOps, data is not a static resource but a dynamic entity that evolves over time. Data pipelines must therefore be designed for reliability, scalability, and traceability.
In a typical MLOps workflow, raw data flows through a series of transformations: ingestion, cleaning, validation, feature extraction, and storage. Each step must be versioned and auditable. Tools such as Apache Airflow, Prefect, and Kubeflow Pipelines orchestrate these data workflows, ensuring that changes are tracked and reproducible.
Data versioning is a cornerstone of MLOps. Just as software engineers use Git to manage code versions, MLOps practitioners employ systems like DVC (Data Version Control) or LakeFS to manage datasets. This ensures that any model can be traced back to the exact data, parameters, and environment used during training.
Moreover, data drift—subtle changes in the distribution of incoming data—can silently erode model accuracy. Continuous data monitoring is therefore essential. Advanced MLOps platforms now integrate automated drift detection mechanisms that alert engineers when the input data diverges significantly from the training data.
By treating data as a first-class citizen, MLOps ensures that machine learning remains grounded in reality, adaptable to change, and accountable for its decisions.
From Experimentation to Reproducibility
Machine learning thrives on experimentation. Data scientists test countless algorithms, hyperparameters, and feature combinations to find the best-performing model. Yet, without systematic management, these experiments can become chaotic—a labyrinth of scripts, notebooks, and undocumented tweaks.
MLOps addresses this challenge through experiment tracking and reproducibility. Tools like MLflow, Weights & Biases, and Neptune.ai allow data scientists to log every experiment—recording model architectures, hyperparameters, metrics, and code versions. This creates a searchable, auditable trail of every decision made along the way.
Reproducibility is more than an academic concern—it is essential for trust and collaboration. When a model performs well, others should be able to reproduce that result exactly, using the same data, code, and environment. This transparency transforms machine learning from an art into an engineering discipline, enabling teams to build upon each other’s work rather than reinventing it.
By integrating experiment tracking with automated pipelines, MLOps transforms trial-and-error into structured exploration—accelerating innovation while maintaining rigor.
Automation and Continuous Integration
The concept of Continuous Integration (CI) is borrowed from software engineering, where automated testing ensures that new code changes do not break existing functionality. In MLOps, CI extends beyond code to include data, models, and configurations.
Whenever a data scientist commits a new model or preprocessing script, CI pipelines automatically test it across multiple datasets and environments. These tests validate not only accuracy but also fairness, performance, and compliance with business rules. Automated checks catch errors early, preventing fragile models from reaching production.
Version control, containerization, and testing frameworks play pivotal roles here. Models are packaged into Docker containers—self-contained environments that guarantee consistency across systems. Continuous Integration servers, such as Jenkins or GitHub Actions, automate the building, testing, and validation of these containers.
This automation replaces manual, error-prone processes with consistent, reproducible workflows. It enables organizations to deploy updates confidently, knowing that every model has passed rigorous quality gates.
Continuous Deployment and Delivery
Once a model is validated, it must be deployed to production—a step that transforms theory into action. Continuous Deployment (CD) automates this process, ensuring that models move from development to real-world environments smoothly and safely.
Deployment strategies vary depending on risk and scale. Some systems use blue-green deployment, where new models run in parallel with existing ones until validated. Others employ canary releases, gradually exposing a small percentage of users to the new model before full rollout.
In advanced setups, deployment pipelines include automatic rollback mechanisms, reverting to previous versions if performance drops. These practices minimize downtime and protect users from unpredictable model behavior.
MLOps platforms such as Kubeflow, MLflow, and Seldon Core simplify these tasks, managing model serving, scaling, and rollback policies seamlessly. The focus is not just on deploying models but on maintaining them as continuously improving assets.
Monitoring, Drift, and Model Governance
A deployed model is not a finished product—it is a dynamic entity that must be continuously observed and maintained. Over time, the world changes: user preferences evolve, sensors degrade, economic conditions shift. These changes, known collectively as concept drift, erode model performance.
MLOps frameworks include robust monitoring systems that track key metrics such as prediction accuracy, latency, and resource usage. They also detect anomalies in input data, signaling potential drift or data corruption. When performance dips below thresholds, retraining pipelines are triggered automatically.
Model governance extends beyond performance. Ethical and regulatory compliance are becoming central concerns in AI operations. Organizations must ensure that models do not propagate bias, violate privacy, or make unexplainable decisions. MLOps provides the infrastructure for explainable AI—tracking model lineage, documenting decisions, and enabling auditability.
Through monitoring and governance, MLOps transforms model management from reactive firefighting into proactive stewardship—ensuring that machine learning systems remain both effective and ethical.
The Infrastructure of Intelligence
Behind every successful MLOps implementation lies an ecosystem of infrastructure technologies designed for scalability and reliability. Cloud platforms—AWS, Azure, Google Cloud—provide the computational backbone for data processing, model training, and deployment. Containerization technologies like Docker and orchestration tools like Kubernetes enable scalability, allowing models to run anywhere, from local servers to global clusters.
Data storage systems—ranging from data lakes to feature stores—serve as repositories for structured and unstructured data. Feature stores, in particular, are central to MLOps, enabling consistent reuse of features across training and production environments. Tools like Feast and Tecton bridge the gap between data engineering and model deployment.
Infrastructure as Code (IaC) practices allow teams to define environments declaratively, ensuring reproducibility and reducing human error. This means every machine learning pipeline, environment, and configuration can be recreated with precision.
By abstracting away complexity, MLOps infrastructure empowers organizations to focus on insights and innovation rather than maintenance and manual setup.
The Human Element: Culture and Collaboration
Despite its technical sophistication, MLOps is ultimately about people. It thrives on collaboration—between data scientists, engineers, analysts, and business stakeholders. It breaks down silos, fostering a culture of shared responsibility where every participant contributes to the lifecycle of machine learning systems.
This cultural transformation mirrors what DevOps achieved in software. MLOps teams embrace iteration, feedback, and transparency. They document experiments, share metrics, and engage in continuous learning. The goal is not merely to deploy models but to create a sustainable feedback loop where human insight and machine intelligence coevolve.
Cross-functional communication becomes vital. Engineers must understand the statistical nuances of models, while data scientists must grasp the realities of system performance and scalability. Successful MLOps organizations invest in training, process alignment, and cultural empathy as much as they do in tools and platforms.
Ultimately, MLOps transforms machine learning from an isolated art into a collaborative craft—one that unites diverse disciplines toward a shared vision of intelligent automation.
Security and Ethical Responsibility
As machine learning systems permeate critical domains—healthcare, finance, transportation—their security and ethical integrity become paramount. MLOps introduces rigorous frameworks for securing data, models, and pipelines against tampering, leakage, and bias.
Model security involves protecting training data from adversarial manipulation, ensuring that models cannot be reverse-engineered, and verifying that deployed models perform only within their intended scope. Encryption, access control, and audit trails form the foundation of these safeguards.
Ethical considerations go hand in hand with technical ones. Bias in data can propagate through models, leading to unfair or discriminatory outcomes. MLOps introduces mechanisms for bias detection, explainability, and accountability. By embedding fairness checks and interpretability tools into pipelines, organizations can ensure that AI serves humanity rather than undermines it.
This confluence of security and ethics transforms MLOps from an engineering discipline into a guardian of trust—a system that ensures intelligent technologies remain transparent, equitable, and aligned with human values.
The Business Impact of MLOps
In the corporate world, MLOps is not just a technical framework but a competitive necessity. It shortens the time between idea and impact, turning insights into deployed intelligence at unprecedented speed.
By automating repetitive tasks, MLOps frees data scientists to focus on innovation. It reduces operational costs by minimizing downtime and manual intervention. More importantly, it enables scalability—allowing organizations to manage hundreds of models across multiple business functions, from marketing optimization to fraud detection.
The business value of MLOps lies in consistency and speed. In a marketplace where data changes daily, the ability to retrain and redeploy models quickly becomes a strategic advantage. Organizations that master MLOps gain the agility to adapt, the reliability to scale, and the foresight to innovate continuously.
In this sense, MLOps is not merely about managing models—it is about managing intelligence itself, as a living, evolving asset that drives business transformation.
The Future of MLOps
MLOps is still a young field, evolving rapidly as machine learning itself advances. The next generation of MLOps will likely be defined by greater automation, democratization, and intelligence.
Automated Machine Learning (AutoML) already streamlines model selection and tuning. Combined with MLOps, it could lead to fully autonomous pipelines that collect data, train models, deploy updates, and monitor performance with minimal human intervention.
At the same time, MLOps will become more accessible. Low-code and no-code platforms are emerging, enabling non-experts to build and manage machine learning workflows without deep technical expertise. This democratization will expand the reach of AI, empowering small organizations and individual innovators.
Edge computing will also transform MLOps. As models are deployed closer to where data is generated—in sensors, vehicles, and mobile devices—new challenges will arise: synchronization, latency, and distributed governance. Future MLOps frameworks will need to adapt, managing not just centralized systems but vast networks of decentralized intelligence.
Perhaps most profoundly, the future of MLOps will intertwine with the ethics of AI. Transparency, explainability, and fairness will become embedded into every stage of the pipeline. In doing so, MLOps will not only operationalize machine learning but humanize it—ensuring that automation remains accountable, interpretable, and aligned with social values.
The Convergence of Intelligence and Operations
At its essence, MLOps represents the convergence of human creativity and machine precision. It bridges the artistry of data science with the discipline of engineering, transforming abstract models into tangible impact. It is not a destination but a journey—a continuous cycle of learning, adaptation, and improvement.
In a world where data grows exponentially and decisions must be made in real time, MLOps stands as the architecture of intelligent operations. It ensures that models evolve as the world does, that automation remains resilient in the face of uncertainty, and that intelligence scales ethically across the fabric of society.
To operationalize machine learning is to give intelligence form and function—to make it serve not only the needs of business but the aspirations of humanity. MLOps is the infrastructure of that vision, the bridge between possibility and performance, between knowledge and action.
And as we continue to build systems that learn, adapt, and evolve, MLOps will remain the quiet force ensuring that intelligence does not merely exist—but endures, responsibly and endlessly, in motion with the ever-changing world it seeks to understand.