In the sprawling digital workshops where artificial intelligence models are trained, errors often wear disguises. They don’t always crash the system or flash warnings. Sometimes, they just quietly ruin everything. These are known as silent training errors—subtle bugs that allow training to continue, unaware that the output is slowly drifting from usable intelligence to computational waste.
For engineers and researchers working on deep learning, especially large-scale models like GPTs or advanced vision systems, these errors are more than a nuisance. They represent lost weeks of work, tens of thousands of dollars in compute costs, and a dangerous illusion of progress. It’s like building a house with bricks that are melting from the inside—you don’t know it’s unstable until it’s too late.
But a breakthrough from the University of Michigan, in the form of a novel framework called TrainCheck, offers a new way to confront this silent crisis. And instead of chasing shadows, it watches the rules.
What If We Could Catch Errors Before They Speak?
TrainCheck isn’t just another monitoring tool. It doesn’t rely on the typical metrics like loss, accuracy, or gradient norms—numbers that, while useful, are noisy and often misleading. These high-level signals fluctuate by design as a model learns. But those fluctuations, natural as they are, create fertile ground for silent errors to hide.
Rather than observing symptoms, TrainCheck focuses on invariants—unchanging truths about the training process that should always hold if the system is functioning properly. Think of them as the laws of physics in a deep learning model’s universe. When one is broken, something has gone deeply wrong.
By automatically inferring and continuously checking these invariants during training, TrainCheck acts like a real-time internal audit. It not only spots when something is amiss but also helps trace the exact moment—and often the cause—of failure.
A Diagnostic Revolution in the Training Room
To understand the power of this framework, imagine training a model with billions of parameters across dozens of GPUs. Something starts to drift. Maybe it’s a misaligned parameter, a faulty data loader, or a random seed that went rogue. But your loss curve looks fine, your validation accuracy is holding steady. You keep going.
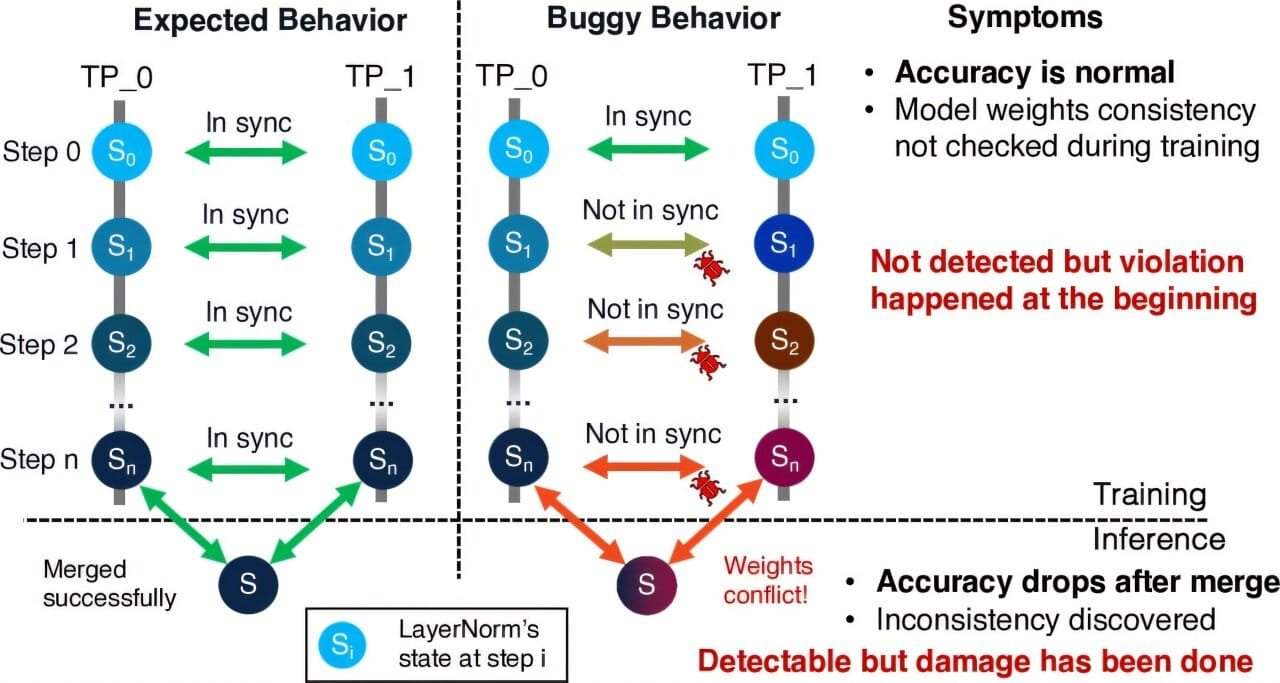
By the time the model finishes, something’s off. It can’t generalize. Its answers feel wrong. You’ve just spent two months on a ghost. This scenario played out in real life when HuggingFace trained their massive BLOOM-176B model. A silent error caused the model replicas on different GPUs to diverge, yielding unusable results—all without triggering any alarms.
TrainCheck was designed precisely for these cases. By focusing on invariant violations, it sidesteps the ambiguity of standard monitoring tools. If a law is broken, it doesn’t matter if the loss looks good—the training is off-course.
Outperforming the Old Guard
When the research team, led by Professor Ryan Huang and doctoral student Yuxuan Jiang, put TrainCheck through its paces, the results were startling. They collected 20 real-world silent training errors from academic papers and community forums—places where developers candidly share their pain points. These weren’t hypothetical bugs; they were drawn from GitHub threads, StackOverflow questions, and the frustrated voices of engineers on social media.
TrainCheck flagged 18 out of the 20 issues almost immediately—often within a single training iteration. By contrast, traditional methods spotted only two.
But detection is only half the battle. The real power lies in diagnostics. In 10 of those 18 cases, TrainCheck’s violation reports identified the exact root cause. In the remaining eight, it pointed within striking distance. By comparison, high-level signal monitors offered useful diagnostic information in just one case.
This isn’t just better detection—it’s a shift in how we think about debugging in machine learning. With TrainCheck, the model isn’t just training—it’s self-watching, evaluating whether its behavior makes sense at every moment.
Precision Without Paranoia
Of course, any detection system that cries wolf too often becomes background noise. But TrainCheck’s alerts were not only accurate—they were manageable. While the system did produce some false positives, these followed recognizable patterns. Developers could quickly identify and dismiss them without derailing their workflow.
This balance—high sensitivity with interpretability—is rare in machine learning infrastructure. It reflects the core design philosophy of TrainCheck: trust, but verify. Let the model learn, but make sure it isn’t breaking its own rules along the way.
Building a Stronger Foundation for AI
In a world increasingly shaped by AI decisions—from search engines to medical diagnostics to autonomous vehicles—the quality of those decisions depends on the integrity of their training. A silent error isn’t just a coding bug. It’s a blind spot in a self-driving car. A misdiagnosis in a cancer screening model. A chatbot that subtly promotes misinformation.
TrainCheck’s contribution, then, is not just technical—it’s ethical. It gives AI engineers a chance to know when something is wrong before the harm spreads downstream. And it restores a sense of agency in a process that often feels like navigating a black box.
The framework is open-source, meaning it’s available to any researcher or company that wants to integrate it into their pipeline. And that’s important—because the more models we train, the more urgently we need systems like this in place.
The Road Ahead: Scaling and Expanding the Vision
The team at the University of Michigan isn’t stopping here. The current version of TrainCheck focuses on invariants in deep learning training, but its underlying principles could be extended to other computational domains—especially in distributed systems where errors propagate in silence.
In the near future, TrainCheck could evolve to offer smart debugging support—suggesting fixes, pointing out probable misconfigurations, or even halting training when catastrophic divergence is detected. Imagine a future where your AI system tells you: “Something’s off, and here’s what you should check.”
They’re also working on adapting TrainCheck for many-model systems, such as federated learning and ensemble training, where errors can ripple across nodes and remain hidden longer. By applying the same invariant-based reasoning, the framework could become a foundational tool for trustworthy AI at every scale.
Guarding the Minds That Shape Tomorrow
Artificial intelligence is the defining technology of our age. But building it requires massive investments—not just in data and hardware, but in trust. Trust that what we’re building is working the way we think it is. Trust that the model we spent months training wasn’t sabotaged by an invisible bug that slipped past every dashboard.
TrainCheck doesn’t make training error-free. But it offers something almost as important: clarity. It turns the opaque into the observable, the silent into the spoken, and the invisible into a flashing signal.
In doing so, it helps ensure that when we hand over responsibility to machines, we know what we’ve built—and can stand behind it with confidence.
Reference: Yuxuan Jiang et al, Training with Confidence: Catching Silent Errors in Deep Learning Training with Automated Proactive Checks, arXiv (2025). DOI: 10.48550/arxiv.2506.14813





