
Imagine you’re watching a suspenseful crime thriller. The detective stares at a blurry photo of a getaway car, clicks “enhance,” and—voilà!—the license plate is crystal clear. For decades, this “zoom-and-enhance” trick has been dismissed as sci-fi fantasy. But now, a team of AI researchers from South Korea may have brought us one giant leap closer to making this trope a reality—though with a few important caveats.
In a new study posted to the arXiv preprint server, researchers Bryan Sangwoo Kim, Jeongsol Kim, and Jong Chul Ye from the Korea Advanced Institute of Science and Technology (KAIST AI) unveiled a powerful new tool they call Chain-of-Zoom, or CoZ for short. This novel framework allows machines to generate ultra high-resolution images by repeatedly zooming in—without any need to retrain the underlying AI models. It’s a clever hack that leverages what already exists in the AI toolbox, and it may be a game-changer for fields ranging from photography to medical imaging.
The Super-Resolution Problem: Why “Zoom In” Has Been So Hard
Before we get into how Chain-of-Zoom works, let’s understand why enhancing images is such a stubborn problem. In the world of computer vision, super-resolution (SR) refers to techniques that take a low-resolution image and try to predict what a higher-resolution version should look like. But this isn’t just a matter of sharpening pixels—it’s about generating entirely new visual information that wasn’t there to begin with.
Most SR models use interpolation, which involves guessing what lies between the pixels, or regression, estimating the most likely values. Unfortunately, these approaches often result in blurry, unimpressive results, especially when attempting to zoom in very far. The more you zoom, the worse the guesswork becomes, making extreme zooms impractical and unconvincing.
Previous attempts to go beyond this hit a wall; they either required massive retraining on specific image types or demanded more computational power than most systems could handle. That’s where Chain-of-Zoom flips the script and offers a fresh perspective.
Chain-of-Zoom: A Step-by-Step Reinvention of Enhancement
Instead of trying to blow up a small image into a big one in a single leap, the KAIST researchers proposed a more human-like process: zooming in step-by-step, cleaning up the view as you go. It’s akin to climbing a staircase to get a better look rather than jumping straight to the top and hoping to land perfectly.
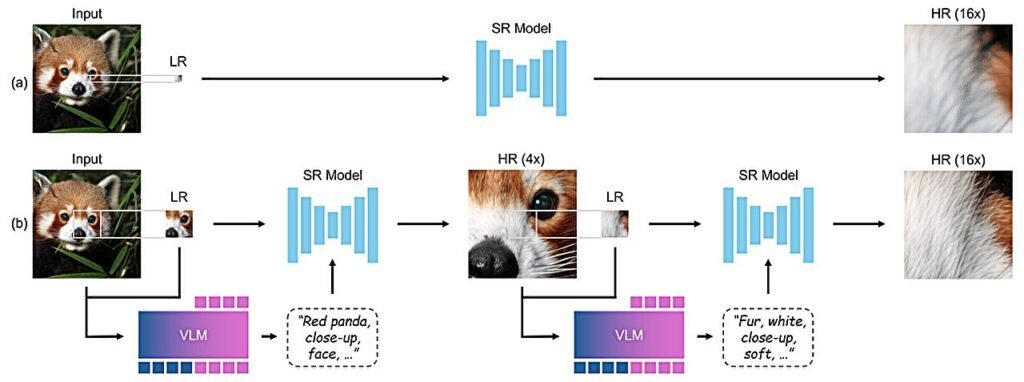
Starting with a low-resolution image, the framework allows a selection of a region to zoom in on. At each zoom step, an existing super-resolution model—which requires no special retraining—is used to enhance that specific region. Meanwhile, a vision-language model (VLM), which acts like a translator describing the scene in words, generates captions or descriptive prompts to guide the SR model in refining the image. This collaboration allows the image to be enhanced incrementally, with the VLM providing useful context at every step.
After the first zoom and enhancement, the framework zooms in again, using the newly refined image and its updated descriptive prompt. This cycle repeats, progressively improving the resolution of the zoomed-in portion until the image reaches a level of detail that satisfies the system or the user’s needs.
The process earned its name, Chain-of-Zoom, because of the linked sequence of zooming and refinement steps. Each stage is connected like links in a chain, with both the image and its descriptive language becoming clearer and more detailed as the process advances.
Prompts That Learn: Reinforcement in Action
One of the most impressive features of CoZ lies in how it fine-tunes the descriptive prompts generated by the vision-language model using reinforcement learning. Typically, an AI might produce a generic description, such as “a red car on a street,” which would offer little help in clarifying tiny details like a license plate.
To ensure the prompts were truly useful for zooming in and enhancing the image, the researchers introduced a feedback mechanism. This system tells the model when a description effectively improved the image or when it should try another approach. Over time, this guided learning teaches the AI to generate better, more informative prompts, improving the refinement process significantly.
This intelligent prompting allows Chain-of-Zoom to achieve remarkable image improvements without the need for retraining any part of the super-resolution model. It’s similar to equipping the model with sharper vision and a better descriptive language instead of asking it to relearn from scratch.
Seeing the Unseeable? Not Quite.
Despite its powerful capabilities, the researchers are quick to caution that the images produced by Chain-of-Zoom are not exact reconstructions of reality. They are enhanced and refined based on AI-generated assumptions, but the resulting high-resolution images are essentially creative interpretations, not guaranteed accurate reproductions.
For example, if the framework were used on a blurry image of a car at a crime scene, it might generate a license plate that looks perfectly clear. However, there is no assurance that this license plate matches the actual one on the car. The AI fills in the missing details based on its training data and the descriptive prompts, producing plausible but not necessarily factual details.
In other words, Chain-of-Zoom doesn’t recover hidden truth; it creates a credible and consistent visualization based on what it “believes” should be there. This distinction is critical, especially in contexts such as law enforcement or legal matters, where accuracy and authenticity are paramount.
Why It Matters: Practical Perks of Chain-of-Zoom
Even with its limitations, Chain-of-Zoom represents a significant leap in generative AI. One of its main advantages is that it does not require retraining the underlying super-resolution models, making it lightweight, adaptable, and easy to incorporate into existing systems.
It works with any current super-resolution model, eliminating the need for new model architectures or massive datasets. Additionally, by generating language prompts alongside image enhancements, the system offers a kind of reasoning or interpretability that can help researchers and developers understand what the AI is focusing on during each zoom step.
Furthermore, the Chain-of-Zoom framework is flexible; it can be scaled to zoom just a little or extensively zoom in, adapting to the user’s needs and computational resources. This versatility makes it potentially useful in many domains, including astrophotography, medical imaging, and digital art restoration.
Looking Forward: A Future of Intelligent Zoom
As AI continues to evolve and fuse vision with language, tools like Chain-of-Zoom provide a glimpse into what’s possible when these capabilities work in harmony. The framework challenges traditional notions of perception and reconstruction, blurring the line between enhancement and imagination.
The KAIST team has opened a new frontier where AI doesn’t just refine what we see—it actively imagines and predicts details. Used responsibly, this technology could help scientists, artists, and researchers push the boundaries of what can be observed and understood.
However, the power of such a system also necessitates caution. Chain-of-Zoom exemplifies that in the era of artificial intelligence, seeing isn’t always believing. While the images produced may look strikingly real, users must remember that the details are AI-generated, not factual data extracted from the original input.
Reference: Bryan Sangwoo Kim et al, Chain-of-Zoom: Extreme Super-Resolution via Scale Autoregression and Preference Alignment, arXiv (2025). DOI: 10.48550/arxiv.2505.18600
Project page: bryanswkim.github.io/chain-of-zoom/





