In a sterile, silent corner of virtual space, a single cube rests under the gaze of synthetic cameras. To the untrained eye, it might seem like just another computer-generated scene. But to a team of researchers in Italy and Scotland, this cube represents the start of something extraordinary: a way to teach artificial intelligence how to imagine what the world looks like from someone else’s point of view.
This deceptively simple cube may hold the key to something deeply human—empathy, perspective, and ultimately, social intelligence.
In a study recently posted to the arXiv preprint server, researchers from the Italian Institute of Technology (IIT) and the University of Aberdeen unveiled a conceptual framework and dataset designed to train cutting-edge Vision-Language Models (VLMs) on spatial reasoning and “visual perspective taking”—the AI equivalent of understanding how a scene appears to another person. The work was born out of the FAIR* project and a collaboration between IIT’s Social Cognition in Human-Robot Interaction (S4HRI) research group, led by Professor Agnieszka Wykowska, and the University of Aberdeen’s Action Prediction Lab, led by Professor Patric Bach.
Their ambitious aim? To bring robots one step closer to understanding the world not just objectively, but socially.
Beyond Seeing: Toward Understanding
Vision-Language Models are powerful AI systems designed to interpret both images and text—recognizing objects, answering questions, or generating captions. But while they can identify what’s in an image, they still lack something essential: the ability to reason about how others experience that same image.
“Visual perspective taking (VPT) is fundamental,” said Davide De Tommaso, technologist at IIT and co-senior author of the paper. “It’s the ability to mentally simulate what a scene looks like from another agent’s viewpoint. That’s what allows us, as humans, to collaborate, communicate, and understand intent.”
Picture a robot helping someone pack a box. If it doesn’t understand what the human can or cannot see—if a label is readable, if an object is behind another, or whether something is within reach—it can’t anticipate needs or respond effectively. The researchers believe VPT could dramatically transform how robots interact in shared environments.
“Our goal is to make robots spatially aware in a human-like way,” said De Tommaso. “This means reasoning about what another person sees, what’s visible or hidden from their vantage point, and adapting behavior accordingly.”
An Artificial World, Carefully Constructed
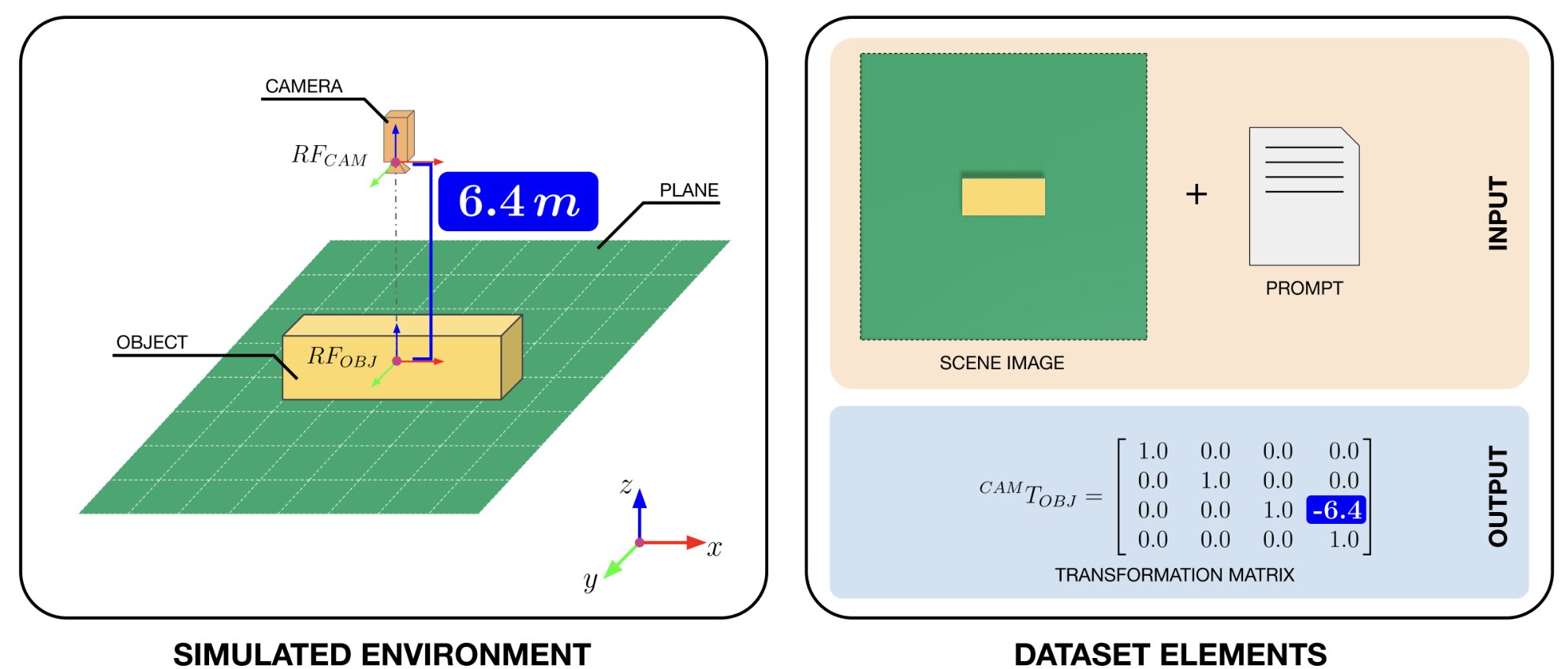
To tackle this challenge, the researchers turned to synthetic data. Using NVIDIA’s Omniverse Replicator—a tool designed to create photorealistic virtual environments—they built a minimalist digital scene: a cube viewed from multiple angles, distances, and perspectives.
Each synthetic image was paired with a natural language description and a 4×4 transformation matrix, which encodes the exact spatial relationship between the virtual camera and the cube. This trio—image, language, and geometry—was compiled into a vast dataset designed to help VLMs learn how to “see” through another’s eyes.
“Each virtual camera gives us a unique angle, and with every image we generate, we also generate a full geometric description,” said Joel Currie, lead author and a Ph.D. student at the University of Aberdeen. “It’s like teaching a robot to step into someone else’s shoes—spatially and cognitively.”
Because the environment is synthetic, the team could create tens of thousands of these image-matrix pairs quickly and under tightly controlled conditions. That level of scale and precision would be nearly impossible in real-world experiments.
“It’s a way of teaching robots to not just process images, but to understand physical space like a being that inhabits it,” Currie explained. “This is foundational to embodied cognition.”
Why Perspective Matters
While the new framework is still theoretical, its implications ripple far beyond academia. The ability to simulate another’s visual perspective could help robots assist people in homes, hospitals, and disaster zones—where anticipating human needs is not a luxury but a necessity.
But this capacity also touches on something deeply philosophical: the notion of shared reality. When we ask someone, “Can you see what I see?” we’re not just speaking literally—we’re reaching for connection. For AI to become truly collaborative, it must participate in that shared perceptual world.
“We know from earlier studies that humans can attribute intentions and goals to robots under the right conditions,” said De Tommaso. “If we give robots better tools to simulate human-like understanding—such as gaze, gesture, or spatial reasoning—they become more relatable, more useful, and ultimately more trustworthy.”
The Road Ahead: From Simulation to Reality
For now, the research is a conceptual stepping stone. The next challenge is to bring these capabilities from the virtual realm into the messy, unpredictable real world. That means narrowing the “reality gap”—the difference between a perfectly simulated environment and the noisy, cluttered spaces humans live in.
“Our next step will be to make the virtual environments more realistic, so the knowledge that a model gains in simulation can actually transfer to physical robots,” said Gioele Migno, a Research Fellow at IIT and co-author of the study. “Once that’s achieved, we can truly begin exploring how spatial reasoning helps robots interact more naturally with people.”
Already, the team is looking ahead to use their dataset to train VLMs capable of real-time perspective reasoning. They hope their open-source dataset will inspire other researchers to create similar synthetic environments—diverse, complex, and tailored to help AI learn how to understand not just objects in space, but their relationship to observers.
“It’s not about giving robots eyes,” Currie added. “It’s about giving them a mind’s eye. A way to imagine the world from someone else’s vantage point.”
The Bigger Picture: Empathy Through Geometry
At first glance, teaching machines to model someone else’s visual field may seem like a dry technical challenge. But at its heart, this research touches on one of humanity’s most defining traits: the ability to imagine another’s experience.
Empathy, cooperation, and social intelligence all stem from perspective-taking. And as robots increasingly enter human environments—from autonomous vehicles to home assistants—the need for them to understand not just what we do, but why, becomes ever more pressing.
What De Tommaso, Currie, Migno, and their colleagues are doing is more than training algorithms. They’re laying the groundwork for a future where machines understand context, adapt behavior, and relate to us on our terms—not through cold calculation, but through something closer to shared understanding.
It starts with a cube in a synthetic room.
But from that cube, an entirely new dimension of artificial intelligence might be built.
Reference: Joel Currie et al, Towards Embodied Cognition in Robots via Spatially Grounded Synthetic Worlds, arXiv (2025). DOI: 10.48550/arxiv.2505.14366