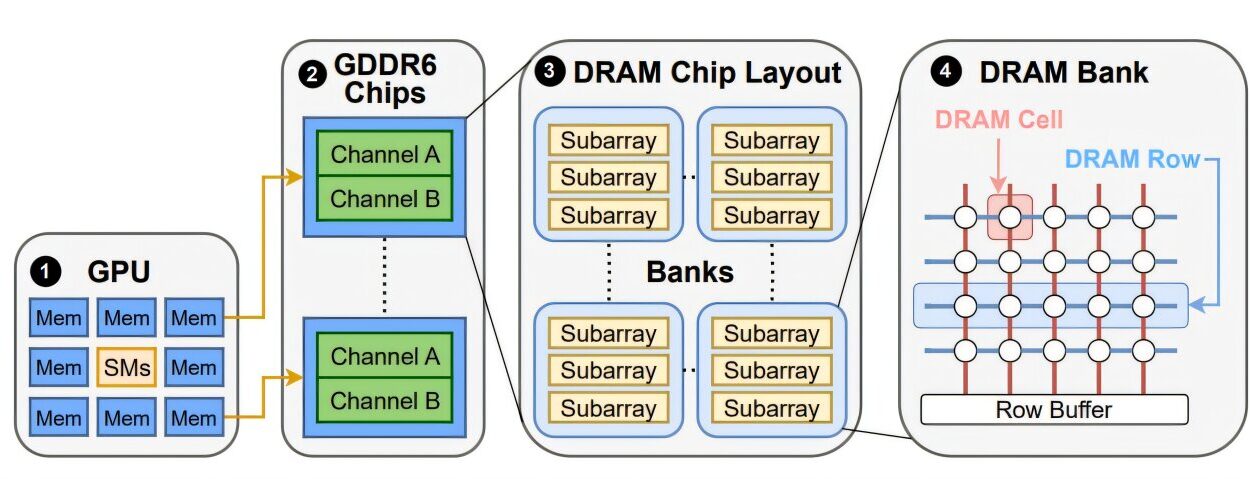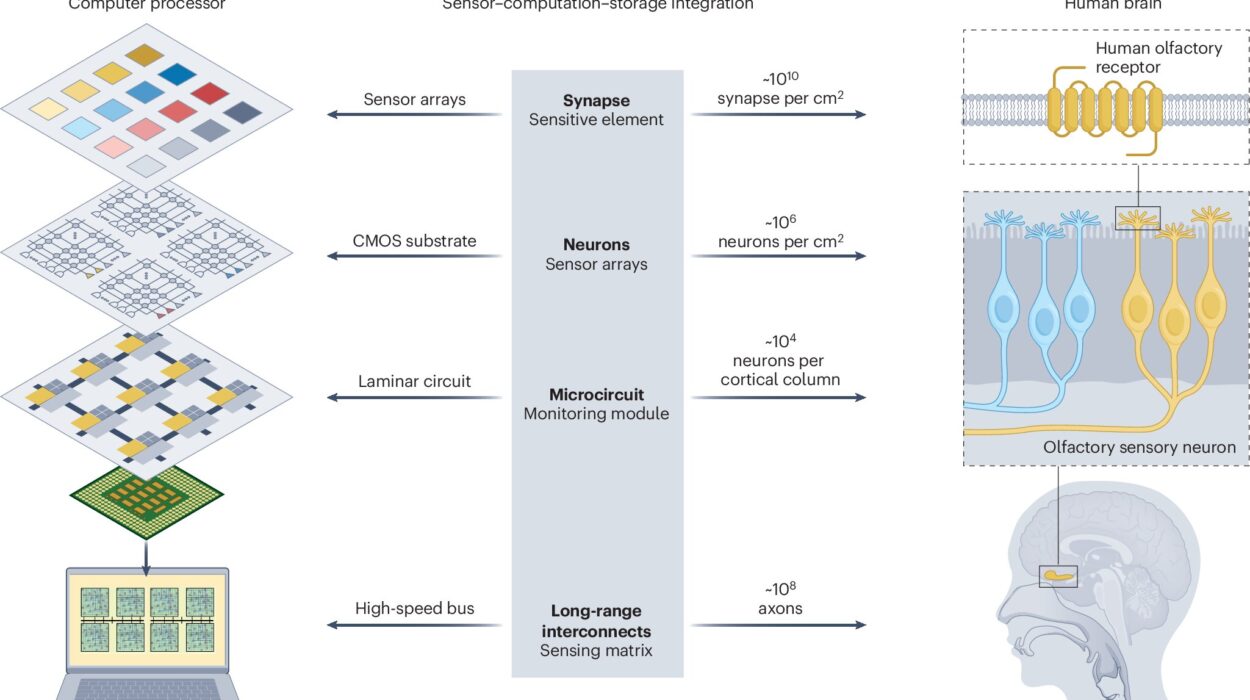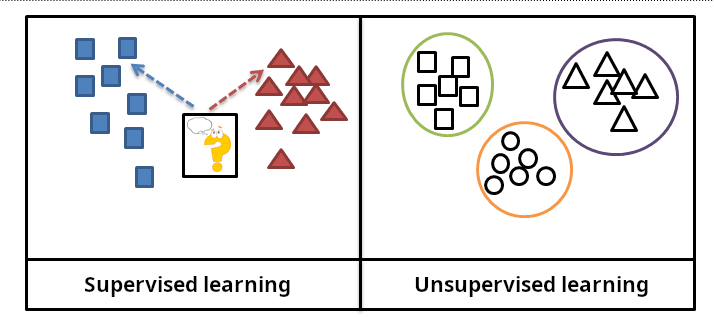
Every day, your life is quietly guided by machines that are learning. They suggest what to watch next on Netflix, filter your inbox, translate your words in real time, drive your car through rush-hour traffic, and even diagnose diseases. This world of intelligent systems seems magical, almost sentient at times—but beneath the surface, it runs on very specific kinds of learning.
At the heart of this transformation are two fundamentally different ways machines learn from data: supervised learning and unsupervised learning. They are not just academic categories. These approaches define how computers make sense of the world, how they evolve, and how close they come to understanding us. Their names may sound clinical, but the divide between them is philosophical—almost existential.
To understand them is to understand the soul of modern artificial intelligence. And like all great contrasts, their difference is not in opposition, but in purpose, in vision, in the role of knowledge and uncertainty.
When the World Gives You Answers: The Realm of Supervised Learning
Imagine trying to learn something new—say, identifying birds. If someone gives you a book with pictures and names beneath each one, your brain immediately begins associating visual patterns with labels. “Ah, this bright red one with a crest? That’s a cardinal.” Your brain starts building a map, linking features to meanings, colors to classifications. This is the essence of supervised learning.
In the world of machines, supervised learning is about guidance. It starts with labeled data—inputs paired with correct outputs. It’s like teaching a child with flashcards, reinforcing knowledge with every example. You give the algorithm thousands of images of dogs and cats, each labeled correctly. Eventually, the machine can tell them apart on its own. Not because it understands what a dog is, but because it’s internalized the statistical differences between them.
It’s an approach that works astonishingly well—so well, in fact, that most of what we consider “AI” today is powered by supervised learning. Image recognition, voice assistants, spam filters, credit scoring, and even cancer detection systems are all built upon it.
But its strength is also its constraint: supervised learning requires answers. Someone, somewhere, must label the data, provide the truth. And when the world is too messy or vast to label completely, this model falters. The machine can’t ask new questions—it can only echo the ones it’s been taught.
Letting the Data Speak: The Mystery of Unsupervised Learning
Now flip the birdwatching analogy. You’re dropped in the jungle, notebook in hand, but no one tells you what any bird is called. No labels, no hints—just a kaleidoscope of colors, feathers, and songs. You begin to group similar birds together. These small blue ones with forked tails? Maybe they belong together. That massive black one with the harsh caw? Surely it’s in a different class.
This is unsupervised learning. No teacher, no answers—just data. It’s the machine version of discovery. The algorithm is left alone with a pile of unmarked information and asked: What patterns do you see?
It’s how Spotify might cluster listeners into taste-based communities without knowing their names. It’s how marketers segment customers. It’s how gene researchers group similar diseases. It’s not about right and wrong—it’s about finding structure in the chaos.
Unsupervised learning is harder to evaluate, more philosophical in spirit. There’s no “ground truth” to compare to. But in return, it allows machines to unearth surprises—insights humans might not have considered, similarities we wouldn’t think to look for. In that sense, unsupervised learning is more creative, more exploratory, more curious.
Learning Under the Hood: Mathematics With a Heartbeat
At the core of both supervised and unsupervised learning is the same fuel: data. But the engines that process that data are built differently.
In supervised learning, the goal is clear: minimize the error between prediction and reality. It’s like trying to guess someone’s age based on their photo and adjusting your formula until you’re right more often than not. Algorithms like linear regression, support vector machines, and neural networks thrive here. They eat data and spit out models that can generalize to new situations—if trained well.
Unsupervised learning doesn’t minimize a known error. It seeks to optimize internal coherence. Algorithms like k-means clustering, principal component analysis, and autoencoders try to group data in a way that feels internally consistent. They search for symmetry, for density, for hidden dimensions.
One optimizes for accuracy. The other optimizes for discovery.
Yet, in practice, the lines blur. Supervised learning often borrows insights from unsupervised methods to preprocess or understand data. Unsupervised learning sometimes leads to labels, which are then used in supervised settings. It’s not a rivalry. It’s a relationship.
The Emotional Landscape of Learning Machines
There’s a deeply human analogy here, and it’s not just poetic. Supervised learning is like formal education—structured, tested, goal-oriented. Unsupervised learning is life itself—messy, open-ended, and full of moments where we discover things we didn’t even know we were looking for.
Consider how we learn language. Parents label things: “This is an apple.” That’s supervised. But over time, we pick up patterns, tones, nuances, sarcasm, humor—without anyone telling us directly. That’s unsupervised. We infer meaning from exposure. We form associations before we have words for them.
This is how machines, too, are growing. And it raises an emotional question: which type of intelligence feels more human?
There’s something almost touching about supervised learning—it learns because we teach it. It depends on us. Every labeled dataset is a conversation, a passing of knowledge.
But unsupervised learning feels more independent. It looks into a sea of noise and pulls out order. It’s as if the machine is trying to understand, not just memorize. It’s where machine learning begins to resemble cognition, even consciousness.
The Limits of Labels: Why Supervision Isn’t Enough
As powerful as supervised learning is, it doesn’t scale infinitely. Labeling data is expensive, time-consuming, and error-prone. Consider trying to label every object in every frame of every surveillance camera around the world. It’s impossible. And even if you could, labels carry human bias. What’s “normal”? What’s “suspicious”? Our definitions leak into the data, and machines learn not truth, but our version of it.
This is where unsupervised learning becomes not just useful but essential. It can explore uncharted territory, identify anomalies, and recognize shifts in distribution—without needing a teacher.
In a rapidly changing world—be it finance, climate, cybersecurity, or social behavior—supervised models may freeze under unfamiliar inputs. But unsupervised systems can adapt. They learn the shape of the data as it is, not as we wish it to be.
The Rise of Hybrid Intelligence
The real future lies not in choosing between supervised and unsupervised learning, but in blending them.
Today’s most advanced systems often begin with unsupervised or self-supervised pretraining—a process where machines learn the structure of data by predicting parts of it. For example, in natural language processing, models like BERT and GPT train by trying to fill in missing words in a sentence—without any human labeling.
Once these models understand the texture of language, they can be fine-tuned with smaller amounts of supervised data for specific tasks like sentiment analysis or translation. This hybrid approach is more powerful than either alone. It mimics how humans learn—first broadly, then specifically.
We explore the world as children without clear instructions. Later, education sharpens our intuition. Machines are following the same arc.
Philosophical Implications: Who Teaches the Machine?
Underneath the algorithms, a philosophical current runs: what is knowledge? Who defines it? In supervised learning, we—the humans—are the ultimate arbiters. We say what’s right. We feed the machine truths carved from our understanding.
But unsupervised learning wrestles with a deeper question: can truth emerge from patterns alone?
This has implications beyond engineering. In journalism, can algorithms detect disinformation patterns without knowing what’s true? In law enforcement, can clustering lead to bias if left unchecked? In science, can machines discover hypotheses we haven’t thought to ask?
The tension here is not just technical. It’s moral. Because once machines begin to learn without us, we must trust their discoveries—or risk becoming the limits of our own invention.
The Emotional Bias in Human Perception of AI
Interestingly, people tend to trust supervised learning more. It’s easier to verify. “The machine said this email was spam, and it was.” But we often feel more awe toward unsupervised learning. There’s something magical about a machine sorting news articles into themes, or organizing music by emotional tone, or discovering new particle interactions in physics datasets.
Unsupervised learning feels like intuition. And perhaps that’s what scares and excites us the most—that a machine might feel its way toward meaning.
The real difference, then, may not be in math but in mood. Supervised learning comforts us. It mirrors our certainty. Unsupervised learning challenges us. It mirrors our wonder.
Real-World Echoes: Lives Touched by Both
Let’s bring this out of the abstract and into the heart of daily life.
When you speak to Siri or Alexa, it’s supervised learning that recognized your words, trained on millions of labeled voice clips. But when Spotify recommends that obscure Icelandic indie band that perfectly matches your soul? That’s unsupervised learning, grouping you with hidden tribes of taste.
When a doctor uses AI to identify a tumor in a scan, that model was trained with supervised learning. But when scientists cluster new variants of a virus based on its mutations, unsupervised models find structure without knowing ahead of time what each variation means.
In online education, supervised learning helps grade essays. But unsupervised learning might one day detect disengagement from subtle behavior patterns—before a student drops out.
It’s not one or the other. It’s both. In everything.
Beyond Today: The Coming Symphony of Learning
The future of machine learning is not binary. It’s symphonic. Self-supervised learning, reinforcement learning, contrastive learning—all these new forms are hybrid offspring of supervision and its absence.
Imagine a robot exploring Mars. At first, it doesn’t know what’s important. It uses unsupervised learning to cluster terrain types, detect anomalies, and map the environment. Later, with occasional updates from Earth, it refines its priorities. It learns to associate certain rock types with signs of life. This is the dance of autonomy and instruction, exploration and feedback.
That’s where we’re headed: machines that learn like humans—curiously, tentatively, and then with purpose.
The Final Contrast: Command vs Curiosity
So what’s the real difference between supervised and unsupervised learning?
It’s not just in the data. It’s in the relationship to truth. Supervised learning is about command. We tell the machine what the world is. Unsupervised learning is about curiosity. The machine tells us what it sees.
One is a mirror of what we know. The other is a window into what we don’t.
And in that sense, they are not opposing forces, but complementary ways of knowing. One builds machines that are useful. The other builds machines that are insightful.
Together, they don’t just make machines smarter.
They help us see the world—and ourselves—with new eyes.