For centuries, humanity has dreamed of reading the mind—of translating thoughts directly into words, images, or sounds. Philosophers once imagined it as magic, and storytellers wrote it into science fiction. But today, that dream is slowly transforming into scientific reality. Modern neuroscience, fueled by artificial intelligence and advanced brain imaging, is beginning to decode the intricate language of the human mind.
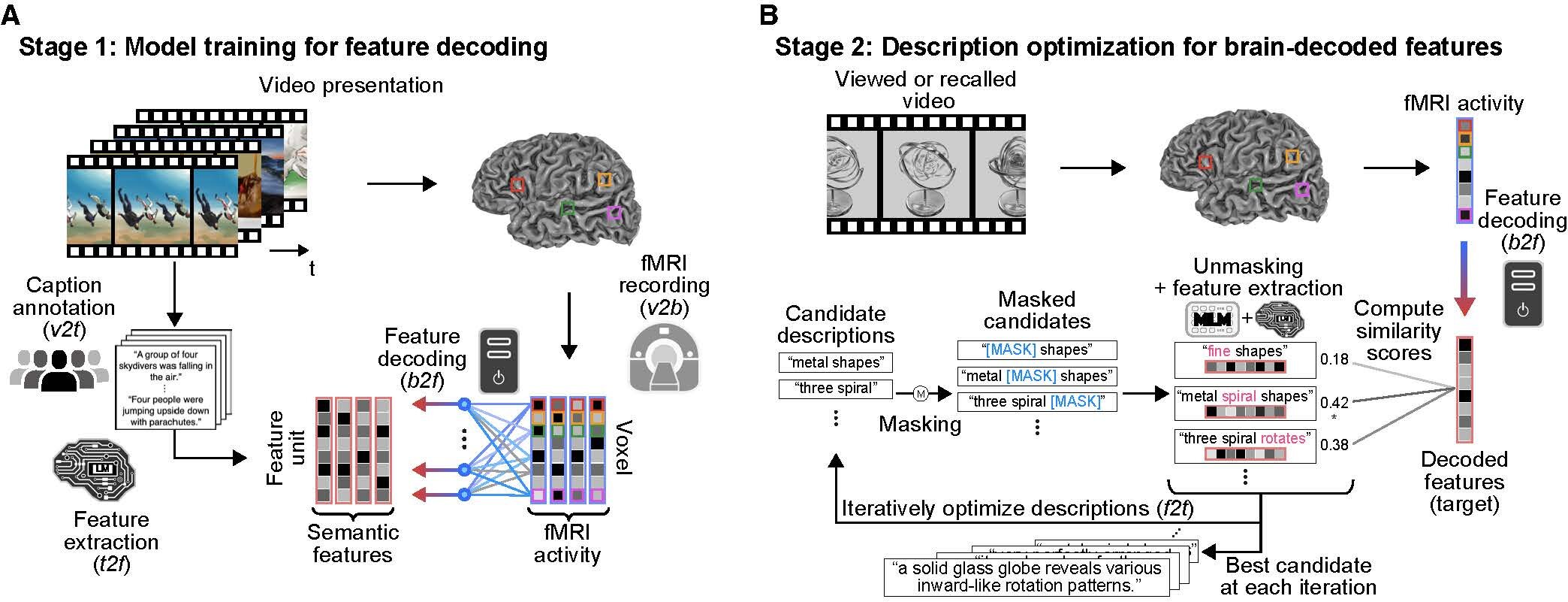
A recent study published in Science Advances represents a leap forward in this effort. Researchers have developed a method they call “mind-captioning”—a groundbreaking technique that translates patterns of brain activity into detailed text descriptions of what a person is seeing, or even remembering. This new approach doesn’t just match brain signals to single words or simple images—it captures the structure, relationships, and meaning behind human perception.
From Brainwaves to Words
For decades, scientists have used tools like electroencephalography (EEG) and functional magnetic resonance imaging (fMRI) to study how the brain responds to stimuli. They could identify patterns associated with specific actions or words, but the results were limited. Previous attempts to “read” brain activity often relied on matching it to pre-existing word databases or object recognition systems. These methods could detect single nouns or verbs but struggled to construct full, coherent sentences that reflected the richness of human thought.
The researchers behind the new study wanted to go further—to generate structured, meaningful language from neural activity. Their goal was to develop a system that could describe entire scenes, events, and relationships between objects, not just isolated ideas. To achieve this, they combined fMRI brain scans with deep language models (LMs)—AI systems trained to understand and generate natural language.
The Birth of “Mind-Captioning”
The key innovation in this study lies in how it merges brain decoding with language modeling. Instead of relying on a fixed database of words, the team used a masked language model (MLM)—a form of AI that predicts missing words in sentences based on context—to iteratively refine its output.
The process began with a “guess”: the model generated rough, fragmented text descriptions based on features decoded from the participant’s brain activity. Then, through repeated cycles of optimization, the system gradually aligned the generated text features with the brain’s semantic features—its representation of meaning—until the description became coherent and accurate.
The researchers describe this as an iterative optimization process, where the machine continuously improves its guesses by comparing them to the brain’s own patterns of meaning. The outcome was remarkable: the system began to produce detailed, structured sentences that captured the essence of what participants were viewing, including complex interactions between multiple objects and dynamic changes in scenes.
Seeing Through the Mind’s Eye
To test the system, the team recruited six volunteers—native Japanese speakers and non-native English speakers. Each participant watched 2,196 short videos while undergoing fMRI scans. The videos showed a wide variety of scenes: people running, animals moving, objects interacting, and landscapes shifting.
While the participants’ brains processed these images, the AI learned to associate patterns of neural activation with specific features extracted from a pretrained language model called DeBERTa-large. This model, which had previously analyzed human-written captions for the same videos, provided a kind of semantic map—a bridge between visual experience and linguistic meaning.
The next step involved another model, RoBERTa-large, which used this information to generate textual descriptions from brain activity. Initially, the generated captions were vague and incomplete. But as the system refined its alignment through iteration, the descriptions grew more accurate and meaningful.
By the end of the process, the AI was able to produce sentences that closely matched what participants were seeing. The system’s accuracy hovered around 50%, a level that significantly outperformed earlier brain-to-text technologies. Even when it failed to name specific objects correctly, it still managed to capture the essence of the scene—conveying motion, relationships, and overall context.
Reading Memory, Not Just Perception
The researchers didn’t stop at visual perception. They wanted to know whether the system could also decode memory—the internal recreation of an experience rather than its direct perception.
In a follow-up experiment, the same six participants were asked to recall the videos they had seen earlier, while their brains were again scanned. The AI then attempted to generate text descriptions of these remembered scenes, using only the participants’ neural activity as input.
The results were striking. The system successfully generated coherent descriptions that reflected the content of the recalled videos. Though accuracy varied between individuals, some participants achieved nearly 40% accuracy in identifying the correct recalled videos out of 100 possibilities.
This experiment demonstrated that the technology could tap not only into the brain’s response to real-world stimuli but also into its inner world of memory—an extraordinary step toward decoding the architecture of thought itself.
A New Voice for the Voiceless
Beyond its scientific intrigue, this research holds profound implications for human health and communication. For people who have lost the ability to speak—such as stroke survivors, individuals with paralysis, or those affected by neurodegenerative diseases—mind-captioning could one day restore a means of expression.
Unlike earlier brain-computer interfaces (BCIs) that focused on decoding single words or selecting letters on a screen, this approach aims to reconstruct natural, contextual language—the kind that carries emotion, intention, and nuance. Because the model aligns with the brain’s representation of meaning, it could theoretically express full ideas rather than fragments of thought.
Imagine a future where a person unable to move or talk could describe what they are thinking or remembering simply through neural signals—where machines act as translators between thought and language. For patients and their loved ones, such technology could mean not just restored communication but the return of dignity and connection.
Ethical Reflections: Reading the Mind and Respecting It
Of course, as with any technology that touches the intimate boundaries of consciousness, ethical questions loom large. If machines can interpret what someone is thinking or remembering, who controls that information? How can we ensure that “mind-reading” technology is used responsibly, with full consent and privacy safeguards?
The researchers themselves are acutely aware of these concerns. They emphasize that their work is conducted under strict ethical oversight, with participant consent and anonymization at every stage. They caution that mental privacy—the right to keep one’s thoughts unobserved—must remain a cornerstone of future developments in brain decoding.
As society edges closer to the possibility of mind-to-text communication, these questions will only grow more urgent. Legislators, ethicists, and scientists will need to work together to establish boundaries that protect human autonomy while allowing beneficial uses of the technology to flourish.
A Window into the Language of the Brain
Beyond its practical applications, the mind-captioning study offers a deeper scientific insight into how the brain organizes meaning. The findings suggest that our brains represent complex experiences—like watching a movie or recalling a memory—in structured semantic patterns that can, in principle, be translated into words.
By combining neuroscience with the power of AI language models, scientists now have a new tool for exploring how thoughts take form. They can begin to map the hidden symmetries between brain activity and linguistic structure—how we convert sensory input into understanding, and understanding into communication.
The study’s authors write that their approach “balances interpretability, generalizability, and performance,” offering a transparent framework for decoding nonverbal thought into language. In essence, it bridges two of the most sophisticated systems in the known universe: the human brain and artificial intelligence.
The Road Ahead
Though the current accuracy rates leave room for improvement, the progress is undeniable. Future iterations of this technology will likely integrate higher-resolution brain imaging, multimodal AI systems, and personalized calibration to each individual’s neural patterns. As the line between neuroscience and AI continues to blur, we may find ourselves entering an era where thoughts can be recorded, analyzed, or even shared.
But for now, the true significance of this research lies not in its novelty, but in what it represents—a merging of biology and technology that brings us closer to understanding the mind’s hidden language. It reminds us that our brains are not isolated machines, but storytellers, constantly generating narratives about the world and our place within it.
The Dawn of a New Kind of Communication
The mind-captioning study opens a door into a future once confined to imagination—a future where silence need not mean voicelessness, and where thought itself can be transformed into language.
As we stand at the threshold of this extraordinary frontier, one truth becomes clear: the human mind is no longer an uncharted mystery. With every advance in neuroscience and AI, we move closer to hearing the inner voice that has always been there—silent, vivid, and waiting to be understood.
More information: Tomoyasu Horikawa, Mind captioning: Evolving descriptive text of mental content from human brain activity, Science Advances (2025). DOI: 10.1126/sciadv.adw1464





