Every modern marvel of artificial intelligence — from voice assistants that greet us by name to self-driving cars navigating complex streets — rests on a foundation we rarely see: the labeled data that fuels machine learning models. Behind the algorithms, the GPU clusters, and the headlines about AI breakthroughs, there’s an invisible army of annotations, carefully crafted to teach machines how to interpret the world.
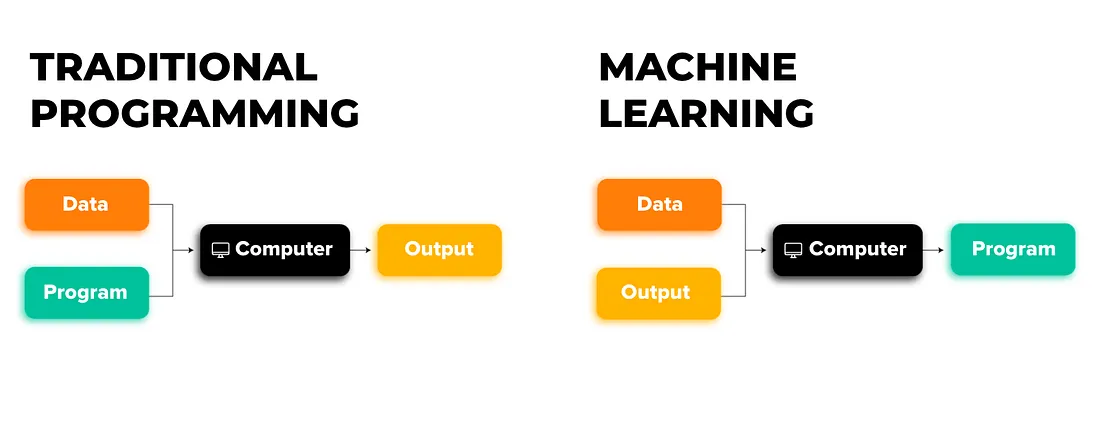
Data labeling is the process of attaching meaning to raw data so that machines can learn from it. Without labeling, an AI sees only pixels, numbers, or waveforms; with labeling, those pixels become cats or road signs, those numbers become transactions or patient vitals, and those waveforms become spoken words or bird songs.
High-quality labeled data is the difference between a chatbot that understands human intent and one that responds like a confused parrot. It’s the difference between an autonomous vehicle that identifies a pedestrian in time to stop and one that mistakes a person for a lamppost.
And yet, data labeling is not a mechanical task to be done in haste. It’s a craft, a discipline, and—when done well—an act of quiet engineering heroism. In this deep exploration, we’ll walk through the best practices that ensure training data achieves the quality machine learning demands, not as a sterile checklist but as a living process full of human judgment, scientific rigor, and ethical responsibility.
The Anatomy of a Label
Before we discuss practices, we must understand what a label is in its purest form. A label is a decision. It’s a moment where a human interprets raw information and translates it into structured meaning the model can digest.
In image classification, that decision may be whether an object in a frame is a “cat” or “dog.” In medical diagnosis, it may be whether a tumor in a scan is malignant or benign. In sentiment analysis, it’s the determination of whether a tweet expresses joy, anger, sarcasm, or despair.
This decision is not made in a vacuum. It’s influenced by the clarity of guidelines, the quality of the raw data, the expertise of the labeler, and the feedback mechanisms in place. A label is the crystallization of a human-machine partnership — one that will determine how the model behaves in the real world.
Setting the Foundation with Clear Labeling Guidelines
Imagine trying to learn a new language where every teacher gives you slightly different definitions for the same word. The result would be confusion, inconsistency, and frustration. Models face the same fate when labeling guidelines are vague or inconsistent.
Clear, comprehensive guidelines are the blueprint of quality labeling. They must define not only the meaning of each label but also the subtle edge cases that can cause disagreement among labelers. For instance, in a project labeling road signs, guidelines must answer: What if a sign is partially obscured? Does a faded sign count as the same category as a fully visible one?
Strong guidelines are written in plain language but backed by examples. They anticipate ambiguity and document the correct course of action. They are not static; they evolve as the project uncovers new corner cases. The best teams treat labeling guidelines as living documents, refining them through iterative feedback and validation.
The Role of Domain Expertise
Not all data labeling is created equal. The stakes in labeling product photos for an online store are vastly different from labeling pathology slides for cancer detection. The latter demands not just attention to detail but medical training and specialized knowledge.
Domain expertise ensures that labels are accurate in contexts where the correct answer isn’t obvious. Without it, even the most diligent labeler can make confident mistakes. For medical imaging, this may mean involving radiologists. For financial fraud detection, it may require analysts who understand transactional patterns.
However, domain expertise must be balanced with scalability. It’s rarely feasible for subject matter experts to label all data. Instead, they can be deployed to create gold-standard reference datasets, review ambiguous cases, and train general labelers to spot important features. In this way, domain knowledge flows into the entire labeling pipeline.
The Human Element: Training and Motivation
Labelers are often invisible in discussions about AI, but they are the first link in the chain of intelligence. Treating them as replaceable cogs is a sure route to poor quality. Well-trained, well-supported labelers can spot subtle patterns, flag problematic data, and adapt to changing project needs.
Training labelers is not just about teaching them to follow guidelines. It’s about helping them understand the purpose of their work and the downstream impact of errors. When a labeler knows that their bounding box will help a car recognize a child crossing the street, their motivation and care increase.
Motivation matters. Labeling can be repetitive, and fatigue leads to mistakes. Rotating tasks, offering breaks, and providing feedback loops keep quality high. Recognition of good work — even in small ways — can transform labeling from mechanical work into a craft.
Quality Control as a Continuous Process
High-quality labeling doesn’t happen by accident; it’s engineered through constant monitoring and correction. Quality control begins with defining acceptable accuracy thresholds and measuring against them regularly.
One powerful method is consensus labeling — having multiple labelers annotate the same data and resolving disagreements. This reveals where guidelines may be unclear and where individual labelers may need retraining. Another approach is gold-standard testing, where labelers are periodically given pre-labeled data to assess their accuracy without their knowledge.
But quality control isn’t about punishment; it’s about improvement. Disagreements are opportunities to refine guidelines. Accuracy drops are chances to provide targeted coaching. A culture of collaboration between labelers, reviewers, and project leads keeps the process healthy.
The Subtle Art of Handling Ambiguity
Real-world data is messy. Images are blurry, text is sarcastic, audio is distorted. The skill in labeling lies not in avoiding ambiguity but in handling it consistently.
Guidelines should specify what to do in uncertain cases, whether that means using a special “uncertain” tag, flagging the data for expert review, or choosing the closest match based on predefined rules. Without a plan, ambiguity leads to inconsistent labeling, which confuses the model.
In some projects, ambiguity can be reduced upstream by improving data collection. Better cameras, clearer transcripts, and more representative sampling can all make labeling easier and more accurate.
Scaling Without Losing Quality
As projects grow from hundreds to millions of data points, the risk of quality degradation rises. Scaling requires both process automation and careful human oversight.
Automation can assist in pre-labeling data using existing models, which human labelers then correct. This speeds up the process without sacrificing accuracy. Active learning techniques, where the model selects the most informative data points for labeling, can focus human effort where it matters most.
But scale must never come at the cost of standards. Even with automation, every label should pass through quality control, and every labeler should receive ongoing feedback.
Ethical Responsibility in Labeling
Labels are not neutral. They can reinforce biases, perpetuate stereotypes, or create harmful outcomes if not handled responsibly. Bias can creep in through skewed datasets, subjective interpretations, or cultural blind spots.
Responsible labeling begins with awareness. Teams must consider who is labeling the data, how their perspectives might influence the labels, and whether the dataset is representative of the real-world diversity it will encounter. Bias audits, diverse labeling teams, and transparent documentation can all reduce risk.
Ethics also extends to the working conditions of labelers. Fair pay, safe environments, and respect for their contributions are not just moral obligations; they directly impact quality.
The Feedback Loop Between Model and Labelers
Labeling is not a one-way street. As models train and begin making predictions, their outputs can reveal weaknesses in the labels. A model that consistently misclassifies a certain class may be highlighting a pattern of errors in the labeled data.
Integrating model feedback into the labeling process creates a virtuous cycle. Misclassified examples can be sent back for review, guidelines updated, and labelers retrained. Over time, this loop raises both model performance and labeling quality.
Documentation and Reproducibility
In machine learning, reproducibility is not just an academic ideal; it’s a necessity. If you can’t trace how labels were created, you can’t diagnose problems when they arise.
Every labeling project should maintain thorough documentation: guidelines, label definitions, training materials, quality control metrics, and records of changes. This creates an audit trail that future teams can use to understand past decisions.
Reproducibility also protects against turnover. Labelers, project leads, and even entire teams may change, but with good documentation, the knowledge stays.
Looking Toward the Future of Labeling
Data labeling is evolving alongside machine learning itself. Advances in weak supervision, synthetic data, and self-supervised learning promise to reduce the volume of manual labeling required. But these methods will never eliminate the need for human judgment entirely.
As models grow more capable, the role of labelers will shift toward creating the rare, high-value labels that teach models subtle reasoning, moral decision-making, and nuanced interpretation. The future will also demand greater transparency, as society asks harder questions about how AI systems are trained and whose perspectives they reflect.
The best practices we’ve explored — clear guidelines, domain expertise, human motivation, quality control, ethical vigilance — are not temporary measures. They are the timeless principles of teaching a machine to see the world clearly.
The Quiet Heroes of the AI Revolution
It’s easy to be dazzled by the breakthroughs in AI and forget the quiet work that makes them possible. Every time a model correctly identifies a tumor, translates a language, or spots a hazard on the road, somewhere in its training history are thousands of moments where a human looked at raw data and made a judgment call.
These judgments, multiplied by millions, are the fingerprints of human care in the age of machines. They are acts of translation between our messy, ambiguous world and the structured realm of algorithms. They are proof that in building intelligent systems, we are also building bridges between human insight and artificial reasoning.
In that sense, data labeling is more than an operational necessity. It’s a shared language — one that teaches machines not just to calculate, but to understand.