Artificial intelligence has transformed the landscape of biomedical research. In just a few years, machine learning models have done what once took teams of researchers years and thousands of dollars: they can predict the structure of proteins, simulate molecular folding, and even propose how drugs might latch onto biological targets. The excitement around these systems is justified. In 2024, the pioneers of protein-folding AI were awarded the Nobel Prize in Chemistry — a rare honor for computational work — recognizing how revolutionary these tools have become.
Yet a new study from the University of Basel issues a sober warning: today’s most advanced AI models can look astonishingly right while being conceptually wrong. Their predictions may seem accurate because they have learned to mimic patterns from past data, not because they understand the physicochemical rules that govern binding in real biological systems. And in drug discovery, where one misjudged structure could cost billions and delay cures by years, “pattern-matching without understanding” is a dangerous illusion.
The Promise and the Trap of Protein-Predicting AI
Proteins are the workhorses of life and the main battlefield of modern medicine. They act as enzymes, receptors, antibodies, hormones, and drug targets. The three-dimensional shape of a protein determines its function — and therefore how a drug might disable, activate, or reshape that function. For decades, mapping protein structures was a painstaking experiment: slow crystallography work, expensive imaging, and long waits.
Then came AI systems like AlphaFold and RosettaFold — tools that can infer the shape of a protein directly from its amino acid sequence. What once took years can now be done in hours. Their success was so dramatic that many began to assume the next step — using AI to predict how drugs (ligands) interact with protein targets — would be just as reliable.
It is precisely this next step that the Basel team decided to stress-test. What they found undermines the comfort many had begun to feel.
A Suspiciously Good Track Record
Professor Markus Lill and his colleagues at the University of Basel were struck by a paradox. AI systems claimed high accuracy at predicting protein–ligand docking, even though they were trained on only about 100,000 known complexes — a tiny dataset compared to modern AI training norms. In other fields, AI models with such little data would struggle. Why were these performing so well on paper?
The team suspected the machines were not reasoning — they were recognizing. Instead of learning why a molecule binds to a protein, they had simply memorized what previously observed binding situations look like. That suspicion was not philosophical; it was testable.
Breaking the Rules on Purpose
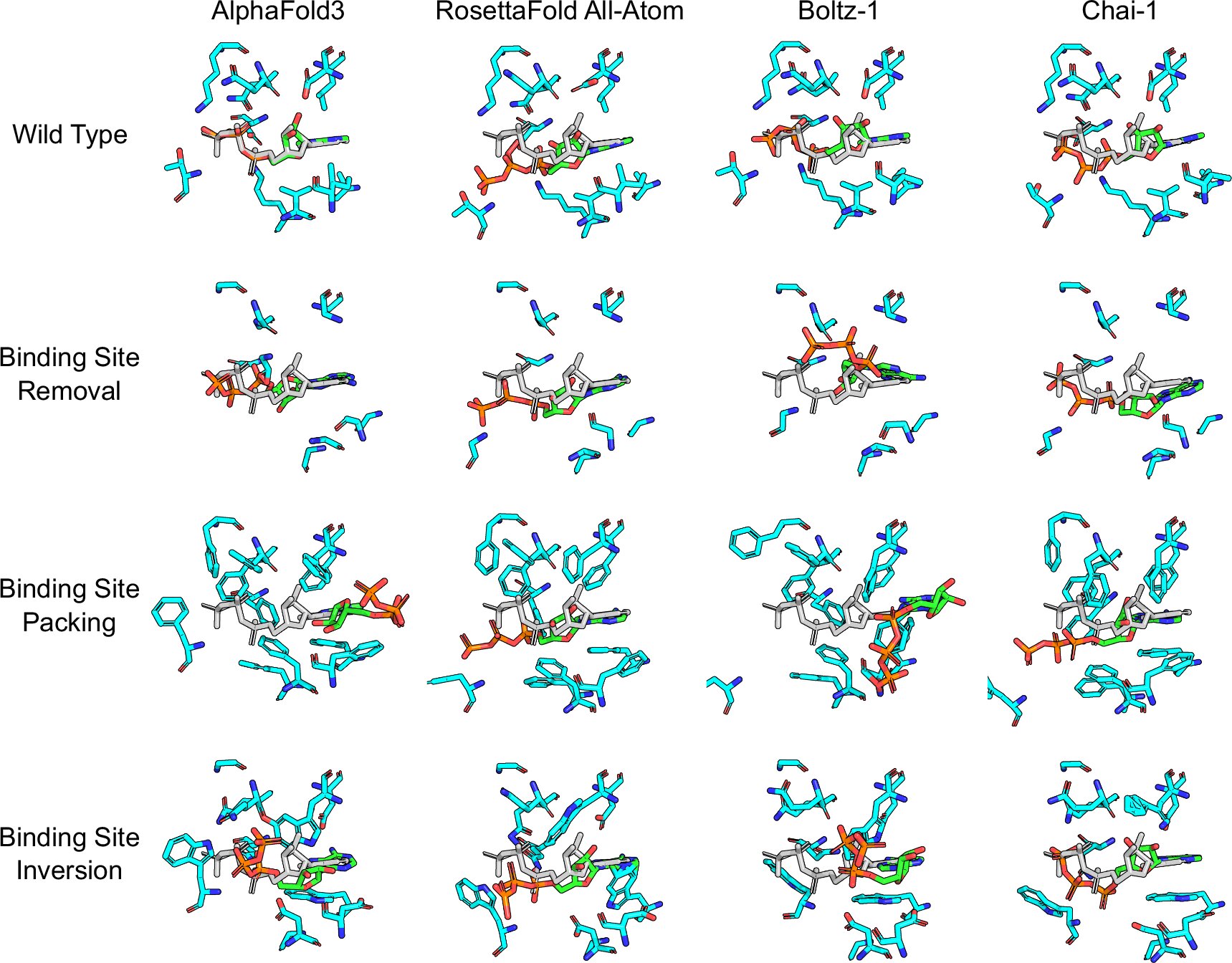
To see whether AI understood physics or merely patterns, the Basel researchers did something clever: they sabotaged the test cases. They took known proteins and subtly rewired their binding sites by changing their amino acid sequence — altering charge distribution or even blocking access entirely. According to chemistry, the ligand should no longer bind. If AI truly understands the physics of binding, its predictions would reflect the disruption.
But the AI models barely noticed. In more than half of the altered proteins, they predicted the same binding structure as if nothing had changed. Worse still, when the researchers modified ligands to make them chemically unable to bind, the AI continued to predict that they would dock successfully. It treated “changed reality” as if it were “old reality in disguise.”
In plain terms: the AI was not analyzing interactions — it was parroting shapes it had seen before.
The Blind Spot That Threatens Innovation
The failure was not symmetric. The models performed especially poorly on proteins unlike those in their training data. This is precisely where drug discovery must look: new targets, rare proteins, and unexplored biological systems. A system that fails exactly where novelty begins is fundamentally misaligned with the needs of pharmaceutical innovation.
Professor Lill’s conclusion is blunt: these models should not be trusted as standalone decision engines in drug design. They offer tempting shortcuts — but shortcuts that give answers without reasons, confidence without justification.
Why This Matters Beyond One Study
Drug discovery lives and dies by physical truth, not computational plausibility. A drug that appears to fit on a screen but fails in a living system wastes years, money, and sometimes lives. AI that merely recognizes patterns could flood research pipelines with beautiful but biologically meaningless predictions. The danger is subtle: not catastrophic error, but systematic misguidance at scale.
The Basel team insists that AI predictions must be verified by experimental or physics-aware computational methods — approaches that actually compute energetics, charge interactions, and thermodynamic feasibility rather than reconstructing familiar-looking geometries.
The Path Forward: Teach AI the Laws, Not the Pictures
The solution is not to abandon AI but to force it to think in terms nature actually obeys. Future models must encode physicochemical constraints, not only statistical resemblance. Instead of learning “what bound structures look like,” they must learn “why binding happens at all.” Such models would move from mimicry toward mechanistic understanding.
If that shift succeeds, AI will become not only a faster mirror of past knowledge but a true generator of biologically plausible futures — tools capable of exploring protein landscapes that have never been imaged and proposing drugs for targets that have never been exploited. That is where the next era of therapeutics will emerge.
A Caution Without Cynicism
The message of the Basel study is not pessimistic; it is corrective. Machine learning has already changed structural biology in ways almost no one predicted fifteen years ago. But a technology becomes dangerous not when it fails, but when its success is misinterpreted. Protein-prediction AI has revealed that the universe is more learnable than once imagined. To fulfill its promise in medicine, it must now learn not only to remember what is seen but to reason about what is true.
Only when AI models are constrained by the same physical laws that govern molecules in the bloodstream will they earn their place as reliable architects of the next generation of drugs. Until then, their brilliance must be treated not as a foundation, but as a hypothesis — one that requires the same scrutiny every scientific tool must endure before it is allowed to shape the future of human health.
More information: Matthew R. Masters et al, Investigating whether deep learning models for co-folding learn the physics of protein-ligand interactions, Nature Communications (2025). DOI: 10.1038/s41467-025-63947-5