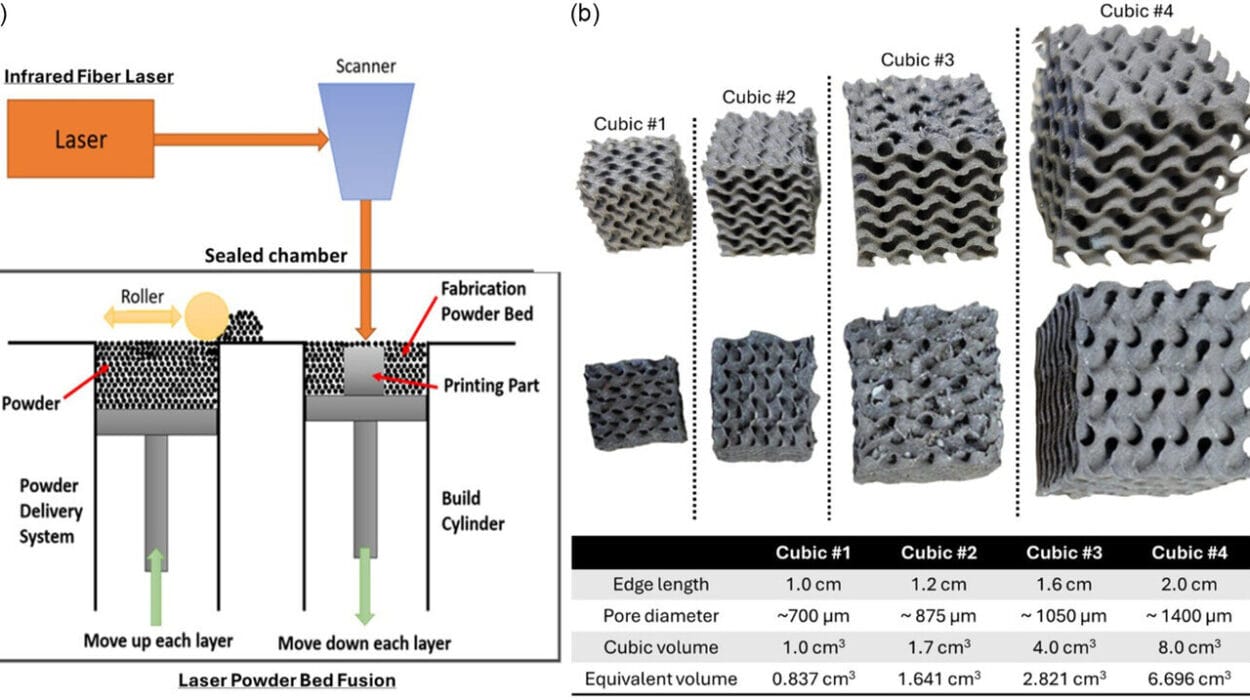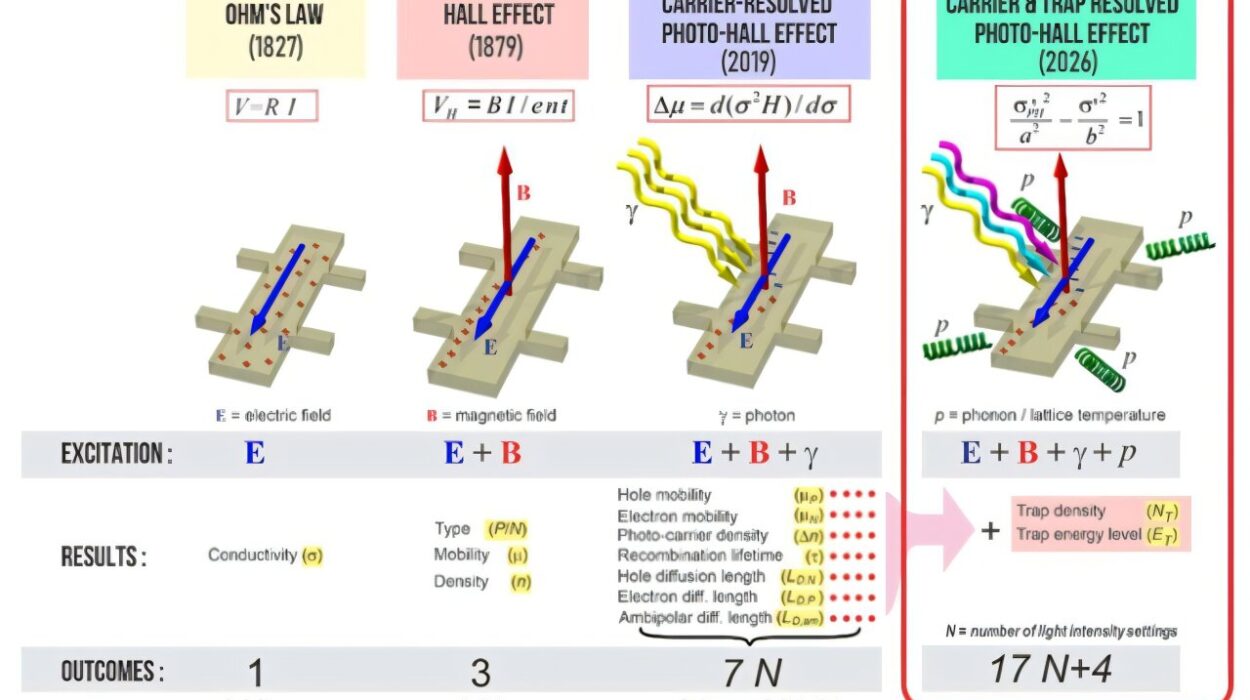
The modern data science landscape is a place of both astonishing possibility and dangerous fragility. A single idea can be tested and deployed in days, yet a single overlooked detail can make that same work impossible to reproduce. In academic research, in business analytics, and in AI engineering, reproducibility is the bedrock of trust. Without it, data-driven conclusions are just stories with numbers attached.
Reproducibility in data science means that someone else — or even you, months later — can take the same data and code and obtain the same results. It sounds simple, almost trivial, but in reality, it is an engineering and cultural challenge. Anyone who has tried to re-run their own old experiments knows the frustration: the missing dependency, the dataset you forgot to back up, the notebook cell you ran out of order, the model that behaves differently after an “invisible” update in a library.
And yet, this challenge is worth solving, because reproducibility is more than a technical nicety — it is a signal of integrity. It says to colleagues, reviewers, clients, and your future self: “You can trust this. This is not magic. This is not luck. This is a process.”
Versioning, notebooks, and pipelines are the three main pillars that, when woven together, create reproducible workflows. They are the infrastructure beneath the art of data science — not glamorous perhaps, but without them, the art collapses.
The Fragile Memory of Data Projects
Imagine you’ve just trained the best-performing model of your career. The accuracy is dazzling, the charts look beautiful, and your boss is impressed. You move on to the next task. Six months later, someone asks you to update the model or explain exactly how you achieved those results. You dig into your project folder, only to find half-documented code, outdated data files, and a notebook where you can’t remember which cells were run, or in what order. You run it again and get a different answer.
This is not incompetence — it’s the default state of human memory meeting complex systems. We forget. We improvise. We tweak something “just to test” and never change it back. In data science, this fragility can cause not just annoyance, but serious harm: flawed scientific papers, broken business forecasts, wasted engineering hours, and mistrust between collaborators.
The tools and practices we’ll explore — version control, literate programming via notebooks, and structured pipelines — exist to combat this entropy. They are how we turn chaotic, fragile projects into living, documented processes that survive the passage of time.
Versioning: The Backbone of Reproducible Work
At the core of reproducibility lies the concept of versioning — not just for code, but for data, configurations, and even model weights. Software engineers have long relied on systems like Git to track changes in code, revert to earlier versions, and collaborate without overwriting each other’s work. For data scientists, the need is broader: you don’t just want to version your scripts; you need to version the whole experiment.
Version control is about creating a time machine for your project. It allows you to answer questions like:
- What did the code look like when we got that result?
- Which dataset was used, and was it cleaned or transformed in any way?
- Did we change the preprocessing pipeline between versions?
By capturing each step in a transparent history, versioning provides accountability. It also enables parallel experimentation: different team members can try different approaches without fear of losing the “good” version.
But standard Git alone is not enough for large datasets or binary model files. This is where tools like DVC (Data Version Control), Git LFS, and similar systems come in, bringing the principles of software versioning to the bulky, ever-changing world of data and machine learning artifacts.
When versioning is applied well, your project gains a narrative. You can look back and see the journey of ideas, the branches explored, the dead ends pruned, and the discoveries made. That history is not just for compliance or audits — it’s a creative record of the evolution of thought.
Notebooks: Storytelling in Code
While version control is the backbone, notebooks are the soul of day-to-day data science. They are where ideas are born, tested, visualized, and explained. A Jupyter Notebook or similar environment is not just a scratchpad — it’s a place where prose, code, and output live side by side, letting you narrate the “why” alongside the “how.”
Notebooks enable literate programming, a term coined by Donald Knuth, where code is written as part of a larger human-readable narrative. This is especially important for reproducibility because it forces the author to explain reasoning, context, and methodology right where the code lives.
However, notebooks are double-edged swords. Their flexibility — the ability to run cells out of order, to keep state in memory — makes them wonderful for exploration but dangerous for reproducibility. If you re-run a notebook from top to bottom and get a different answer than you did during experimentation, you’ve lost reproducibility.
The antidote is discipline. Keep notebooks clean, with a clear top-to-bottom execution order. Avoid hidden state. Record the environment: the Python version, the library versions, the dataset version. Where possible, automate the environment recreation with tools like conda environments or Docker containers.
When maintained with care, notebooks become more than just interactive code — they become living documents of the experiment. A well-kept notebook lets someone else, or you in the future, step back into the exact moment of insight and walk the same intellectual path.
Pipelines: Orchestrating Complexity
As projects grow, individual scripts or notebooks become insufficient to handle the complexity. This is where pipelines enter the scene. A pipeline is a structured sequence of data processing and modeling steps, each one reproducible, testable, and replaceable.
Pipelines enforce order. They define how raw data is transformed, cleaned, and fed into models. They capture parameters, intermediate outputs, and dependencies between steps. This structure makes it possible to re-run the entire process with a single command — a massive improvement over trying to remember which notebook to run first, and with which arguments.
Pipeline frameworks like Apache Airflow, Luigi, Kubeflow Pipelines, or lighter tools like prefect or snakemake bring engineering rigor to data science. They allow you to build workflows that can be scheduled, monitored, and reproduced automatically.
In the context of reproducibility, pipelines solve two problems at once: they prevent “works on my machine” syndrome by making the process explicit, and they make scaling to larger datasets or distributed environments much easier.
Most importantly, a pipeline is a form of documentation. It’s a map of the project’s logic, showing how each step leads to the next. Even if the original authors disappear, the pipeline remains as a guide for anyone who needs to reproduce or extend the work.
The Human Side of Reproducibility
It’s easy to focus only on the technical side of reproducibility — the tools, the commands, the configurations — and forget that reproducibility is fundamentally a cultural practice. No tool can force someone to care about versioning their data, documenting their notebooks, or structuring their pipeline.
Teams must cultivate a shared value system where reproducibility is part of the definition of “done.” That means code reviews that check for documentation, pull requests that include environment files, and pipelines that run automatically in continuous integration systems to catch broken steps early.
It also means kindness toward your future self. Documenting every detail may feel tedious now, but it is an act of generosity to the person you’ll be in six months, struggling to remember what “final_model_v3.ipynb” actually did.
The most successful reproducible workflows emerge in teams that treat documentation and structure not as bureaucracy, but as an extension of creativity — a way to make their ideas not just possible, but sustainable.
Reproducibility in the Era of Machine Learning Ops
As data science merges more deeply with production software, MLOps (Machine Learning Operations) has emerged as the engineering discipline that binds together reproducibility, deployment, and monitoring. MLOps is about treating machine learning systems with the same rigor as any other critical software system — which means versioning datasets, tracking experiments, and automating pipelines are non-negotiable.
Experiment tracking tools like MLflow, Weights & Biases, and Neptune.ai extend the idea of versioning beyond code and data to include metrics, parameters, and artifacts from each run. This makes it possible to reproduce not just the final result, but the entire path taken to get there.
In MLOps, reproducibility is not an afterthought; it is the foundation. A model that cannot be reproduced cannot be trusted, and a model that cannot be trusted has no place in production.
The Emotional Payoff of Doing It Right
There is a deep satisfaction in knowing your work will outlast your current attention span. When you version your code and data, maintain clean notebooks, and build pipelines, you’re not just making life easier for collaborators — you’re preserving the spark of your own insight for the future.
It’s the difference between leaving behind a pile of puzzle pieces and leaving behind a completed picture, with the process for building it clearly outlined. That completeness is a form of craftsmanship, and in data science, craftsmanship is rare and valuable.
Looking Toward a Future of Shared Knowledge
Reproducibility is not just about individual projects. It is about building a culture where knowledge is shared openly, where experiments can be verified and extended by others without having to reinvent the wheel. In academia, this means publishing code and data alongside papers. In industry, it means building internal repositories of well-documented, reusable workflows.
When we build reproducible systems, we make it easier for others to learn from us, build on our work, and push the field forward. We turn our personal experiments into stepping stones for collective progress.
Conclusion: The Triple Helix of Trust
Versioning, notebooks, and pipelines are not isolated tools. They form a triple helix of reproducibility: versioning ensures we can see the evolution of our work, notebooks capture the narrative and reasoning, and pipelines formalize the process into something executable and scalable.
Together, they create not just reproducible data science, but trustworthy data science. And in a world where data is both abundant and easily manipulated, that trust is the most valuable currency we have.